正文
xLSTM(Extended Long Short-Term Memory)是一种通过引入指数门控,残差连接,并行架构对传统 LSTM(Long Short-Term Memory)模型进行扩展和改进的新时序模型。
xLSTM由sLSTM和mLSTM交替堆叠构成。其中,作者通过修改LSTM的存储结构,构建了具有标量存储和标量更新的sLSTM和具有矩阵存储的完全并行化的mLSTM。
sLSTM
sLSTM的结构如图所示。
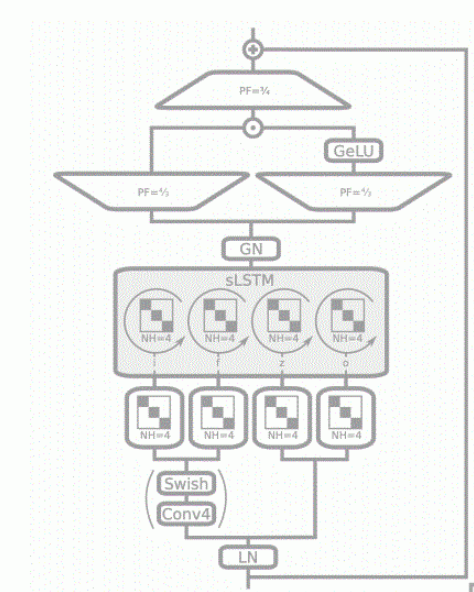
相比于LSTM,sLSTM在记忆单元中假如指数门控(输入们和遗忘门的sigmoid变为指数函数exp()),并对隐状态进行标准化。sLSTM的输入通过一个kernel_size为4的因果卷积,该卷积层采用swish激活函数,用于输入门和遗忘门。随后将输入门i、遗忘门f、输出们o和记忆细胞更新z,通过具有四个对角块的块对角线性层。最后,隐状态通过组归一化层(GroupNorm Layer)对每个记忆头进行归一化,使用带有GeLU激活函数和投影因子为4/3的门控MLP进行上投影和下投影。
因此sLSTM在时间步t的更新规则如下:

由于指数门可能会导致溢出,作者引入稳定状态mt来稳定门控,因此新的输入门、遗忘门更新规则如下:

mLSTM
mLSTM的结构如图所示。
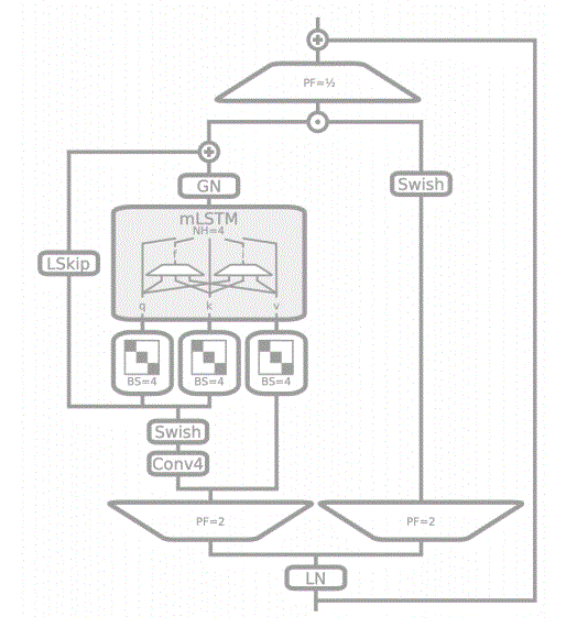
mLSTM将记忆单元中的记忆细胞从标量扩展到到矩阵,允许xLSTM模型捕获输入数据中更复杂的关系,从而提高需要理解序列任务的性能。mLSTM外层结构同样为层归一化残差结构。在进行投影因子为2的投影后,分别作为外部输出们和mLSTM记忆单元的输入。对于记忆单元的输入,同样采用kernel_size为4和激活函数为swish的因果卷积进行特征提取。随后,使用四个对角块的块对角投影矩阵进行线性变换,得到q、k、v,其中v跳过卷积层,由记忆单元的输入进行线性变换得到。隐状态在输出后进行组归一化,并与可学习跳跃输入(LSkip)相加,在经过下投影后,与残差连接进行相加后输出。
与sLSTM相同,mLSTM也引入稳定状态mt来稳定门控,但mLSTM中多个记忆单元是等价的,没有记忆混合现象,因此可以将mLSTM的循环计算重构为并行计算。具体而言,mLSTM在时间步t内的更新规则如下:
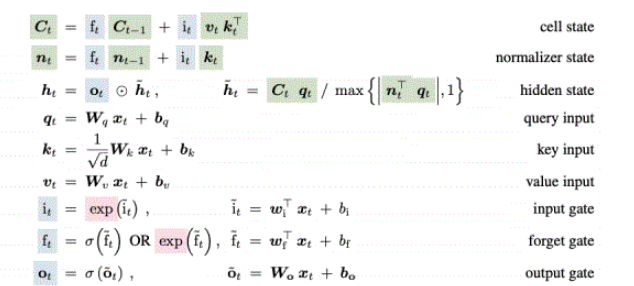
在sLSTM和mLSTM的构建中,kernel_size为4的causalConv被用于处理输入数据。causalConv只关注当前和过去的操作,不会获取未来的信息,使其在处理时序数据时不违反时间的因果关系,这对于序列预测任务非常重要。
然而,因果卷积的感受野取决于卷积核的大小,虽然可以通过堆叠多个卷积层来扩大感受野,但每一层卷积的本质仍然是在捕获局部特征,在长距离依赖问题中仍然具有局限性。
自注意力机制被广泛用于各种深度学习任务中,其允许序列中的每个位置直接与所有其他位置进行交互,通过计算查询、键和值之间的相似度分数,并进行加权求和来生成整个输入序列的计算结果。在流量检测任务中,流量数据具有很强的时序性。
为了使模型更好地捕捉和利用这种时序信息,我们提出一种改进的xLSTM模型,名为CAxLSTM。通过引入因果注意力机制代替causalConv,重新构建sLSTM块和mLSTM块。
因果注意力机制通常对自注意力权重矩阵A添加一个掩码矩阵M,该矩阵满足公式:
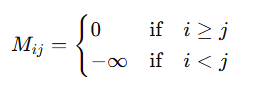
矩阵M的上三角部分(未来时刻)为负无穷,下三角部分(过去时刻)为0。在与原始权重矩阵A进行相加后得到Amask矩阵,如公式所示。
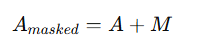
矩阵Amask的下三角部分仍然为原始权重,而上三角部分变为负无穷大(表示模型获取该部分信息)。通过这种掩码操作,在Softmax计算后,上三角部分权重变为0,这意味着模型只能关注到过去及当前时刻的时间步信息。
最终,本文采用由一个sLSTM块和一个mLSTM块构成的CAxLSTM作为MBLB模块的最后一层。