正文
这是一份为您量身定制的标准化项目流程文档。本次更新已严格保留了您提供的所有细节,去除了 Mermaid 图表中的所有标题序号,并在核心部分为您配上了严谨的 LaTeX 公式。
检索增强生成系统标准流程文档
2.1 文档入库
- 哈希计算:对全文计算内容 Hash,用于唯一标识和变动追踪。
- 倒排索引:构建文档的倒排索引,用于后续的 BM25 检索。
2.2 向量嵌入
- 切分参数:设置 Chunk Size 为 900,Overlap 为 150。
- 文档展开:使用
markitdown按 Markdown 格式展开文档结构。 - 边界断开策略:优先在 Markdown 结构边界断开(如标题、段落、代码块、分隔线等),严格避免在代码块内部切分。
- 切分算法步骤:
算法说明:这样即使某个断点是标题(结构分高),如果离目标太远也会被惩罚;反过来,离目标很近但结构很弱的断点也不会轻易胜出。综合起来就是“兼顾结构边界与长度目标”。
- 先把所有可能断点打“结构分”(例如:标题得分高、空行得分低等)。
- 当文本长度接近目标长度时,在一个“回看窗口”内挑出候选断点。
- 对每个断点再加“距离惩罚”:离目标长度越远分数越低,离目标越近分数越高。
- 最终用 **“结构分 × 距离衰减系数”** 选出最佳断点。 + **向量生成与存储**:为每个 Chunk 生成持久化向量。采用 `float32` 数据类型,向量维度为 1024,嵌入模型使用 `qwen3-0.6b-Embedding`。向量数据全量存储到 Milvus 数据库。
2.3 查询步骤
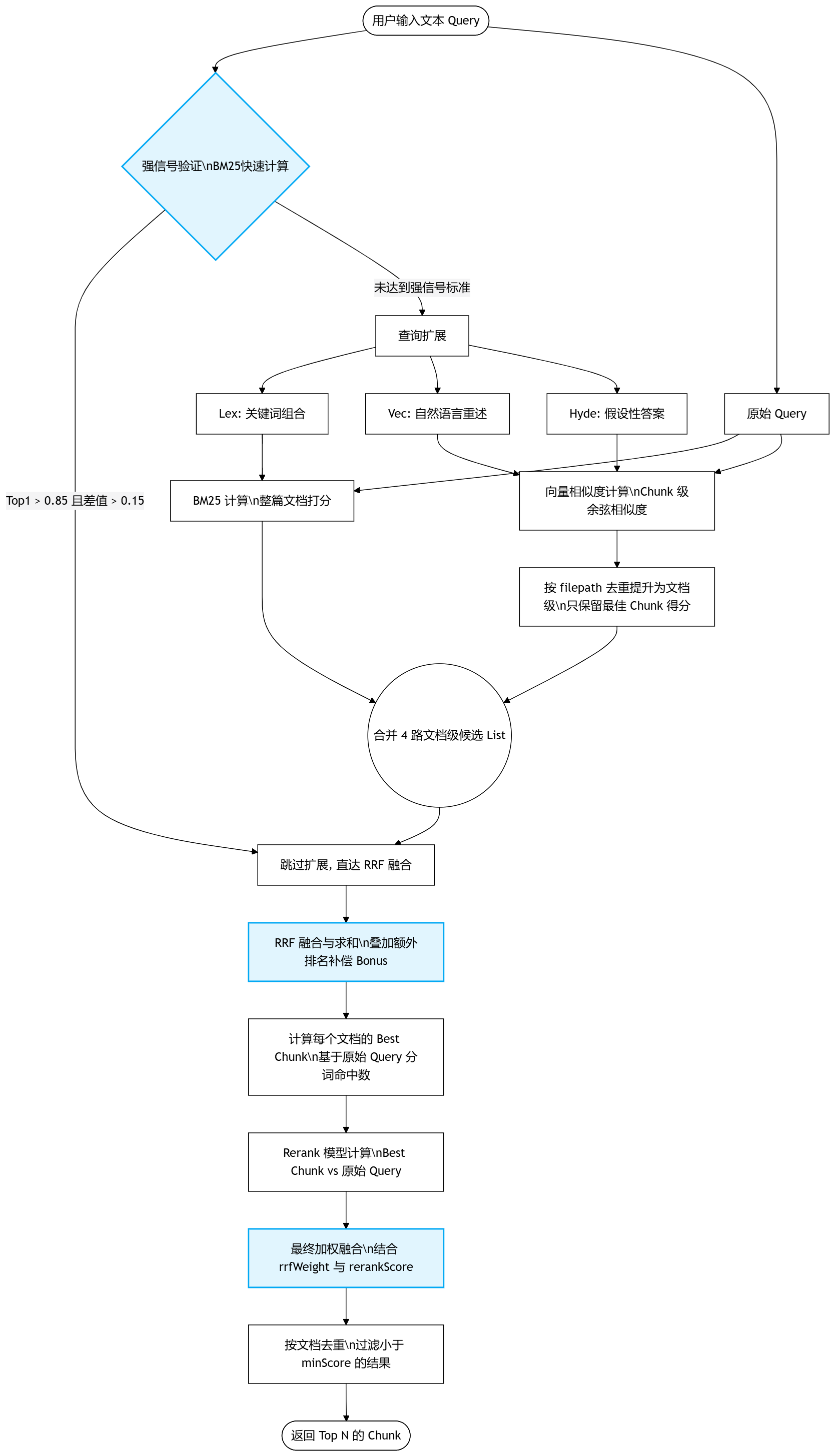
用户输入文本 Query 后,系统开始执行查询流水线。
2.3.1 强信号验证
先做一次 BM25 检测快速计算结果。若结果为强信号,直接跳到 RRF 融合步骤。
- 强信号定义:Top 1 得分高(
 )且与 Top 2 拉开明显差距(
)且与 Top 2 拉开明显差距( ),视为“强信号”,可跳过后续查询扩展以节省成本。
),视为“强信号”,可跳过后续查询扩展以节省成本。
2.3.2 查询扩展
调用大模型生成以下扩展内容:
- Lex:关键词组合。
- Vec:将问题用自然语言重述。
- Hyde:生成假设性答案(Query 的假设结果)。
2.3.3 计算
分为 4 条分支进行计算:Lex、Vec、Hyde、原始 Query。
- 计算方式分配:
- Lex:仅参与 BM25 计算。
- Vec、Hyde:参与向量相似度计算。
- 原始 Query:参与 BM25 + 向量相似度计算。
- BM25 计算:会对整篇文档的内容进行打分排序。
- 向量相似度计算:在 Chunk 级别进行余弦相似度计算,随后提升至文档级。
提升文档级示例:
向量检索原始命中(Chunk 级):
docs/a.md#chunk0距离 0.12(得分 0.88)docs/a.md#chunk3距离 0.18(得分 0.82)docs/b.md#chunk1距离 0.20(得分 0.80)去重提升为文档级(按 filepath):
docs/a.md只保留最佳 Chunk(0.12),文档得分 0.88,记录 chunkPos=chunk0docs/b.md保留 chunk1(0.20),文档得分 0.80
2.3.4 RRF 融合
- 每条计算分支会给出一个候选文档级 List。
- 将每条分支的结果进行 RRF 融合,得到每个文档的融合分数。
- 对同一文档的 RRF 分数求和,得到该文档的初始合并分数。
- 排名补偿计算:计算文档在所有文档中的最佳排名
 。若存在排名第一,最终分数
。若存在排名第一,最终分数  ;若排名第二、三,最终分数
;若排名第二、三,最终分数  。公式如下:
。公式如下:

- 这一步骤的输出是文档级候选列表,每条包含融合后的
score = rrfScore。
2.3.5 每个文档的 Best Chunk
遍历候选文档,计算文档中每个 Chunk 命中 Query 关键词(原始 Query 的分词)的数量。分数最高(命中数最多)的 Chunk,作为该文档的 Best Chunk。
2.3.6 Rerank
将每个文档的 Best Chunk 送入 Rerank 模型,与原始 Query 进行计算,得到 rerankScore。
2.3.7 最终融合
根据 RRF 的名次重新定义 RRF 基础得分和权重分配:

根据 RRF 名次决定权重  :
:

计算最终分数:

设计说明:这样高位文档更“信任检索”,低位文档更“信任 Rerank”。最终的 finalScore 也是文档级的,因为每个文档只提供一个 Best Chunk。
2.3.8 去重、过滤
按文档进行去重,过滤掉最终分数小于 minScore 的结果。最后返回 Top N 的 Chunk。
流程示意图