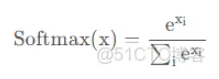正文
激活函数常用的:ReLU、GeLU、Softmax、sigmoid、Tanh。
激活函数对精度不敏感。
激活函数是应用于神经元输入的数学运算。非线性对于网络学习输入和输出之间的复杂映射至关重要,使其能够捕获数据中的复杂模式。
激活函数的作用
- 激活函数是神经网络每一层神经元输出的非线性变换。 引入非线性是核心作用。
如果没有激活函数,网络每一层都是线性变换:
- y=Wx+b
多层线性叠加仍然是线性变换:
- y=W2(W1x+b1)+b2
- =(W2W1)x+(W2b1+b2)
- **问题**:无论有多少层,都只能表示线性关系,无法拟合复杂函数。 2. **控制输出范围**(部分激活函数) + Sigmoid → [0,1],可表示概率 + Tanh → [-1,1],适合中心化数据 3. **稀疏性/梯度控制**(例如 ReLU) + ReLU 将负数置零,输出稀疏,有助于梯度传播 + GELU/LeakyReLU 对梯度消失问题有缓解作用
对于这句话的理解:ReLu会将负值变0,更像是一个 “开关”。好处是 可以减少计算量,原始10个神经元,其中7个是负的,那么只需要计算剩下3个即可,使其更像是生物的神经系统,选择性激活。
即使将某些神经元的负值变为0,也不是真正的消失,因为在下一层中 会通过激活、神经网络等方式,利用这个”0”,将这个维度的值重新编码、计算,得到新的值。
丢掉部分负值,在神经网络训练中,可能是有益的。有利于减少冗余、加速训练、防止过拟合(自带正则化)。同时保证,梯度稳定传播。
神经网络是多层网络,负值所代表的信息不会真正丢失,只是被重编码。如果负值确定不想丢弃,可以使用leakyReLU,通过α参数控制负值的缩放比例。
ReLU
ReLU(x) = max(0, x)
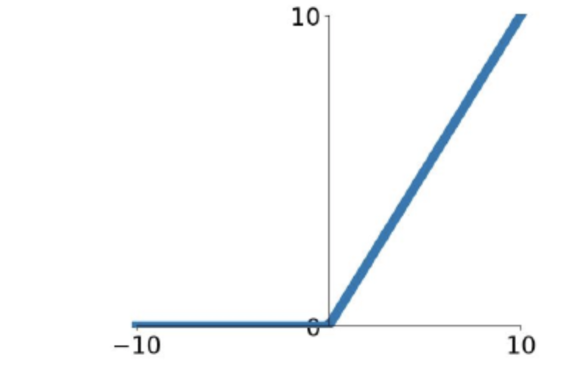
优点
- 简单高效,计算量小
- 梯度传播稳定
- 输出稀疏, 类似生物神经元稀疏激活 → 减少冗余
缺点
- 负半轴梯度为 0 → 可能产生死神经元。这里死神经元 指的是置为0后,在后续计算中一直为0,导致权重不更新。
- 不适合输出概率
如何避免ReLU出现死神经元?
- 合理初始化权重:Xavier、He 初始化,避免初始输入全为负
- 批量归一化(BatchNorm):调整输入均值,使 ReLU 输入不总是负值
- 改进: Leaky ReLU 、GeLU、ELU
GeLU(Gaussian Error Linear Unit,高斯误差线性单元激活函数)
tanh版本的GeLU:
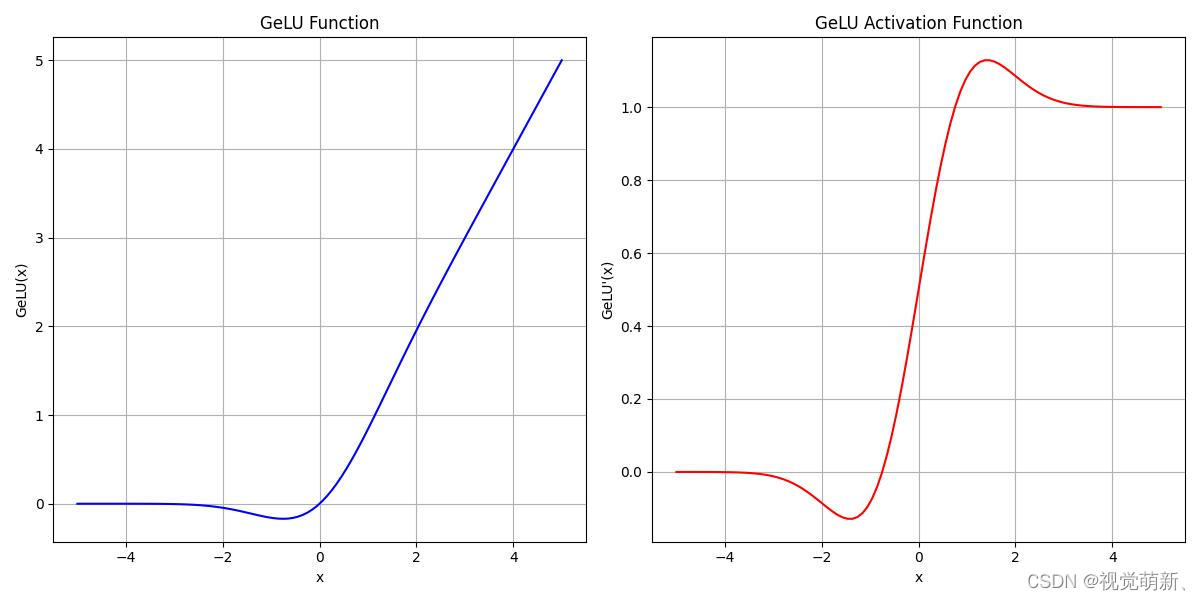
GeLU 由 Dan Hendrycks 和 Kevin Gimpel 在 2016 年的论文“高斯误差线性单位 (GELU)”中介绍,因其增强神经网络学习能力的能力而受到关注。
与其前身ReLu不同,GELU 是从标准正态分布的累积分布函数 (CDF) 的平滑近似得出的。
这是我们的输入乘以此时的标准正常 CDF:
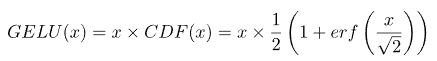
erf 是高斯误差函数。它是许多标准数学和统计库中得到良好支持的函数。
在其原始公式中,GeLU **不能用于我们的神经网络,因为该函数复杂且计算速度慢。为此,可以引入tanh版本的GeLU,用tanh近似高斯误差函数erf。**
在这里,我们使用函数 近似高斯误差函数:
近似高斯误差函数:
 向函数引入线性分量
向函数引入线性分量 将双曲正切函数应用于输入,这有助于保持平滑过渡
将双曲正切函数应用于输入,这有助于保持平滑过渡- 缩放因子
 应用归一化,确保输出在合理的范围内
应用归一化,确保输出在合理的范围内
还有一个更简单的基于 sigmoid 的近似值:

这些近似值通常被认为是准确的,尽管 和 erf 的 尾部不同。在实践中,
尾部不同。在实践中, 近似功能良好,很少需要进一步细化和更复杂的实现。
近似功能良好,很少需要进一步细化和更复杂的实现。
特点
- 平滑非线性:负值渐进接近 0,正值接近 x
- 梯度稳定:全局导数连续,负值区域仍有梯度。(处处可导,用于预防梯度爆炸)
- 非稀疏:输出不一定为零,但保留信息
优点
- 对深层网络友好,训练稳定
- 避免死神经元
- 在 Transformer、BERT、GPT 等模型表现优秀
缺点
- 计算量比 ReLU 稍大
Softmax
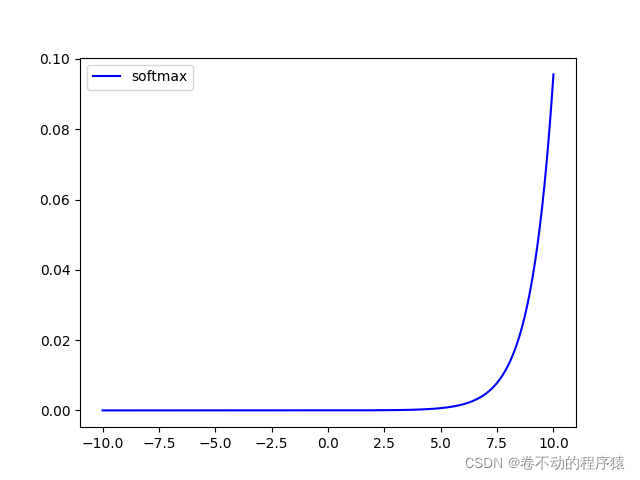
softmax核心操作是指数运算, **这使得它对输入的 **微小变化 比线性函数更加敏感 Softmax一般用来作为 神经网络的最后一层 ,用于多分类问题的输出。 其本质是一种 激活函数 ,将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。
exp是指数函数。等价于 e^x
公式: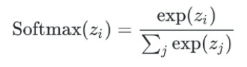 或
或