正文
简单易懂:https://zhuanlan.zhihu.com/p/677607581
写在前面:首先要搞懂RL的目标是什么?RL在NLP领域中,是如何应用的?我们之前看的视频都是讲标准的RL,控制游戏小人前后左右,但NLP领域与之不同。
RL 基本概念(截图)

NLP中的 RL 概念
须知:模型在在做推理时,是一个token一个token的蹦。
目的
希望给模型一个prompt,让模型能生成符合人类喜好的response。
概念
- 我们先喂给模型一个prompt,期望它能产出符合人类喜好的response
- 在 t 时刻,模型根据上文,产出一个token。这个token即对应着强化学习中的动作,我们记为At 。
- 因此在NLP语境下,强化学习任务的动作空间就对应着词表。每次动作的空间范围即为词表大小。
- 在 t 时刻,模型产出token 对应着的即时收益为Rt,总收益为Vt(复习一下,Vt蕴含着“即时收益”与“未来收益”两个内容)。这个收益即可以理解为“对人类喜好的衡量”。此刻,模型的状态St从变为St+1,也就是从“上文”变成“上文 + 新产出的token”
- 在NLP语境下,智能体是语言模型本身,环境则对应着它产出的语料。
RLHF-PPO中的4个模型
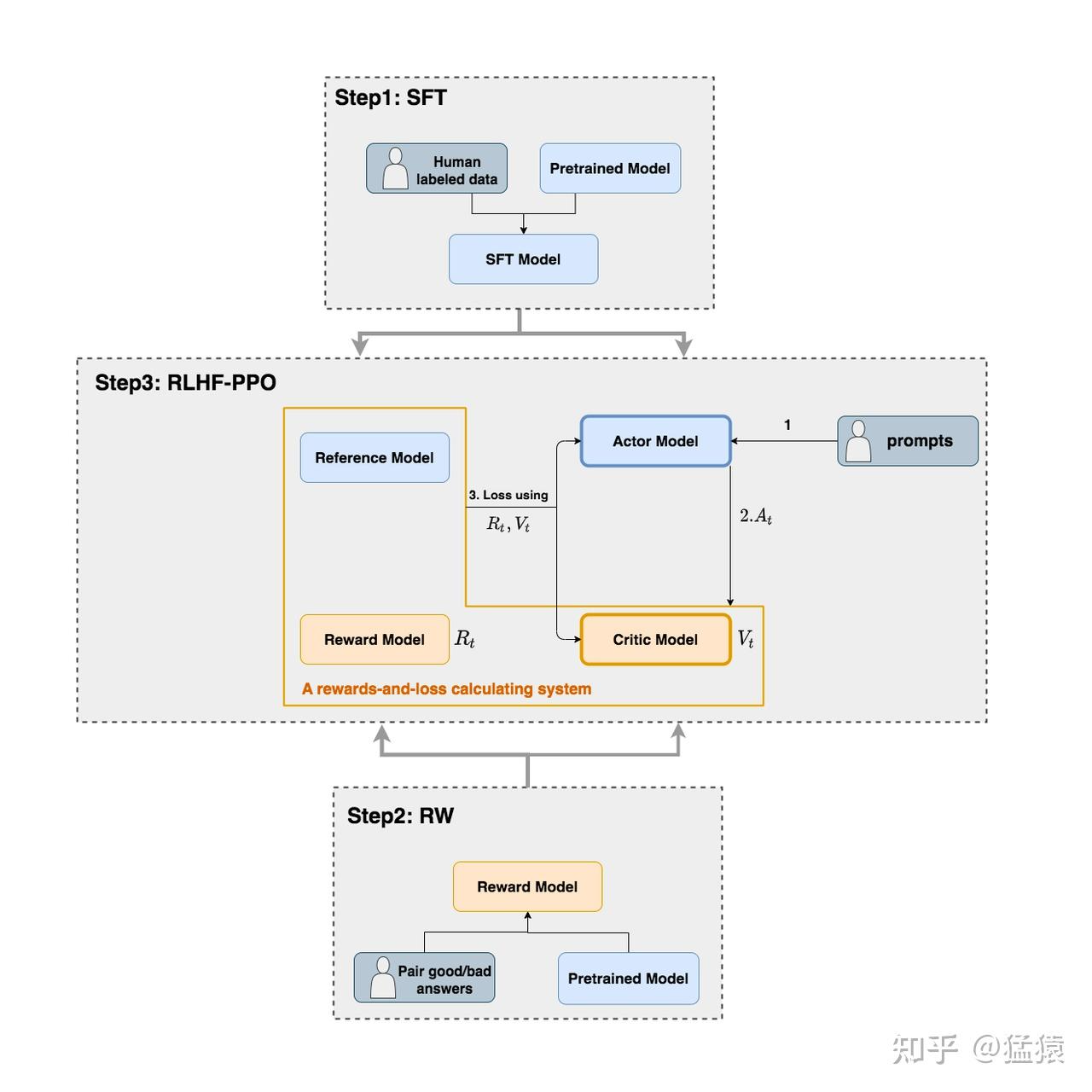
如上图,在RLHF-PPO阶段,一共有四个主要模型,分别是:
- Actor Model:演员模型,这就是我们想要训练的目标语言模型
- Critic Model:评论家模型,它的作用是预估总收益Vt
- Reward Model:奖励模型,它的作用是计算即时收益 Rt
- Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)
其中:
- Actor/Critic Model在RLHF阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义)
- Reward/Reference Model是参数冻结的。
- Actor model由SFT阶段的模型初始化而来。
- Reference Model 也由SFT阶段模型初始化而来,但权重冻结,不会更新。
- Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系(自己命名的),我们综合它们的结果计算loss,用于更新Actor和Critic Model
Actor Model (演员模型)
Actor就是我们想要训练的目标语言模型。我们一般用SFT阶段产出的SFT模型来对它做初始化。
目的是,让Actor模型能产生符合人类喜好的response。所以我们的策略是,先喂给Actor一条prompt (这里假设batch_size = 1,所以是1条prompt),让它生成对应的response。然后,我们再将“prompt + response”送入我们的“奖励-loss”计算体系中去算得最后的loss,用于更新actor。
注意:这里如果batch_size =2,则同时输入2条prompt,利用2条prompt的结果计算loss。
Reference Model(参考模型)
Reference Model(以下简称Ref模型)一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。原文:“防止模型训歪”换一个更详细的解释是:我们希望训练出来的Actor模型既能达到符合人类喜好的目的,又尽量让它和SFT模型不要差异太大。简言之,我们希望两个模型的输出分布尽量相似。那什么指标能用来衡量输出分布的相似度呢?我们自然而然想到了KL散度。
- 对Actor模型,我们喂给它一个prompt,它正常输出对应的response。那么response中每一个token肯定有它对应的log_prob结果呀,我们把这样的结果记为log_probs。
- 对Ref模型,我们把Actor生成的”prompt + response”喂给它,那么它同样能给出每个token的log_prob结果,我们记其为ref_log_probs
- 那么这两个模型的输出分布相似度就可以用
**ref_log_probs - log_probs**来衡量。
第一次看没看懂,这是后面自己的理解:
问题:什么是log_probs?回答:官方解释是,对于给定token,模型会预测这个token出现的概率p。但由于概率值p一般很小,直接用的话数值不稳定,为了方便计算取其对数(log)形式。例如预测”cat”的概率p为0.2,log_prob=log0.2≈-1.6。直到模型预测完整段文本的token,就得到了最终的log_probs。
同时要知道,每次预测下一个token时,其实都会给出词表中每一个token的概率p,在经过一些采样策略(topK、topP)筛选后,在所有剩余token中选择一个作为NTP(next token prediction)的最终结果。log_prob取的就是这个最终采样的结果,而不是全部token。ref_log_probs也是同理。
问题:把Actor的”prompt + response”送给Ref模型是为什么?Actor是将prompt输入进去,然后根据得到response计算log_prob,Ref Model为什么不输入prompt而是”prompt + response”?
回答:并非官方答案,只是个人理解。
是为了根据response中的每个token,得到Ref Model预测Prompt时,出现response中的每个token的概率p,进而计算该token 的ref_log_prob。
如果只传Prompt输入到Ref Model,根据LLM的概率采样规则,可能会与Actor的response结果不同。2个不同的response没办法计算KL散度,比较也无意义。
因此需要Ref Model“照着答案,翻课本,找到对应的页码”。答案就是response,页码就是response中的token的概率p。
假设:
prompt: "我喜欢"
Actor 生成的 response: "吃苹果"
token 序列(假设分成 3 个 token):
["吃", "苹", "果"]
- Actor log_probs
Actor 生成这 3 个 token 时,对应概率分别是:
吃:0.4 → log_prob=-0.916
苹:0.5 → log_prob=-0.693
果:0.6 → log_prob=-0.511 - Ref log_probs
Ref 接收完整的"我喜欢 吃 苹 果",在每个位置上算出“出现该token”的概率:
吃:0.38 → log_prob=-0.967
苹:0.55 → log_prob=-0.598
果:0.58 → log_prob=-0.544
然后做:

问题:Ref模型如何做到根据”prompt + response”得出ref_log_probs?
回答:任何语言模型的背后,都是在计算概率分布。即使模型最终输出的是Str,但内部仍然是计算了token, 只是我们平时用它时只取了概率最大的那个 token 来拼成字符串。
任何语言模型(无论是 SFT、Actor 还是 Ref)在推理时,内部都是这样工作的:
- 输入 prompt → 经过 Transformer 网络 → 输出一个向量(logits),logits 的维度 = 词表大小(比如 50,000)。
- 对 logits 做 softmax → 得到 每个 token 的概率分布。
- 采样(或者 greedy 取最大概率)得到一个 token ID,这里可能有一些采样策略,如topK\topP。
- 把这个 token 拼回字符串(经过 tokenizer 解码)。
- 把新 token 加到 prompt 末尾,再重复步骤 1~4,直到生成结束。
完整个人理解:
- Ref模型的主要作用是防止Actor”训歪”
- Actor可能训的过程中只看奖励了,若不加限制,可能导致与原来SFT模型差别较大、风格变化大、语法变化大、会有一些为了高奖励而“走捷径”的奇怪输出。
- 为此需要进行惩罚,引入KL 惩罚项(KL散度)来“拉回”Actor ,KL散度需要2个模型。
- KL 散度越小,说明两者分布越接近,模型“没训歪”;越大,说明 Actor 输出已经和 Ref 差别很大,需要惩罚。