正文
MoE模型与Dense模型的区别
- MoE模型又叫 专家混合模型、稀疏模型,Dense模型又叫 稠密模型。
- MoE模型可以理解为,将Transformer中的FFN 替换为了一个专家网络(多个MLP + 门控网络)。
- 下面是Qwen3 MoE和Dense的区别,基本上只有MLP有区别。
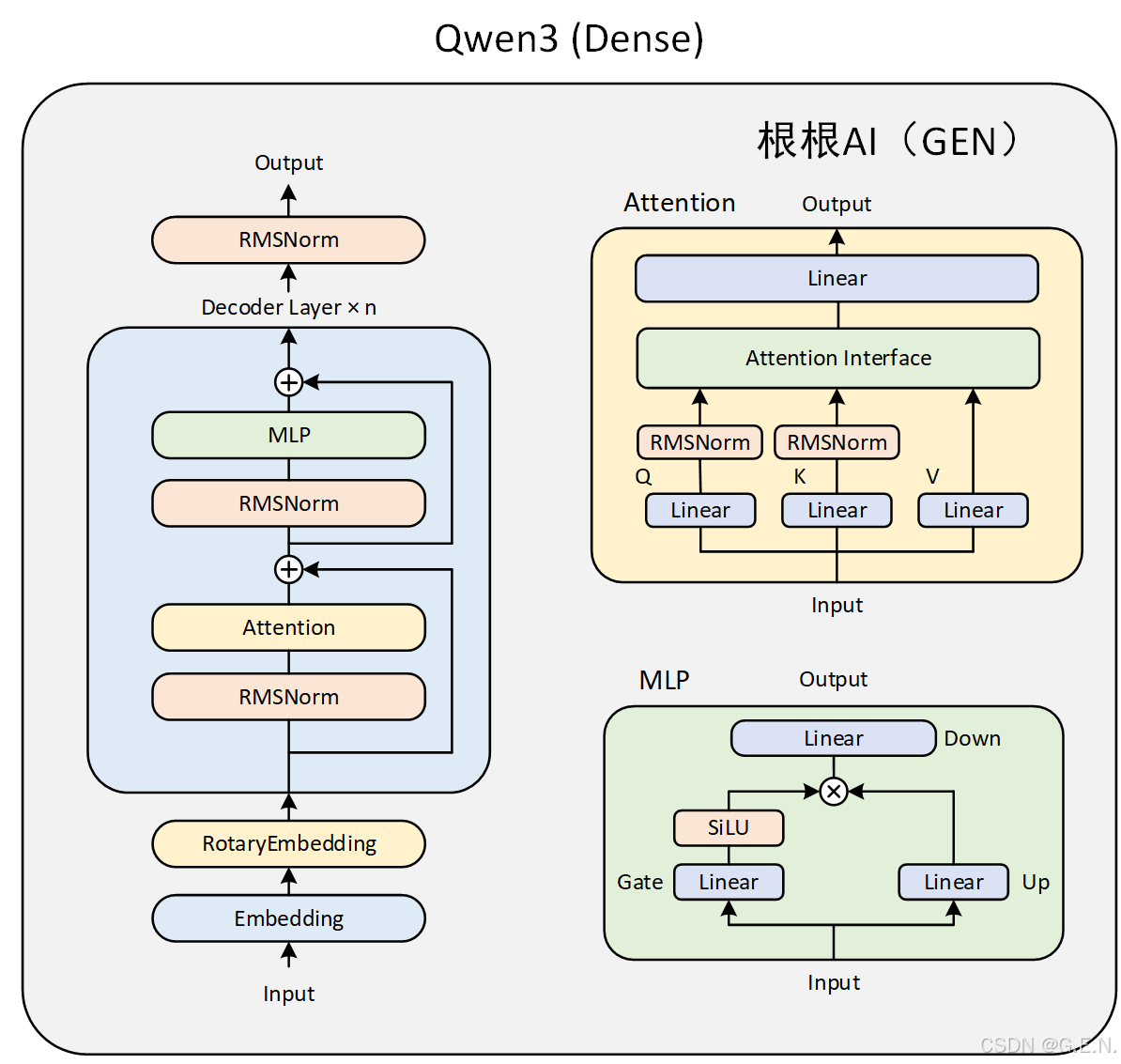
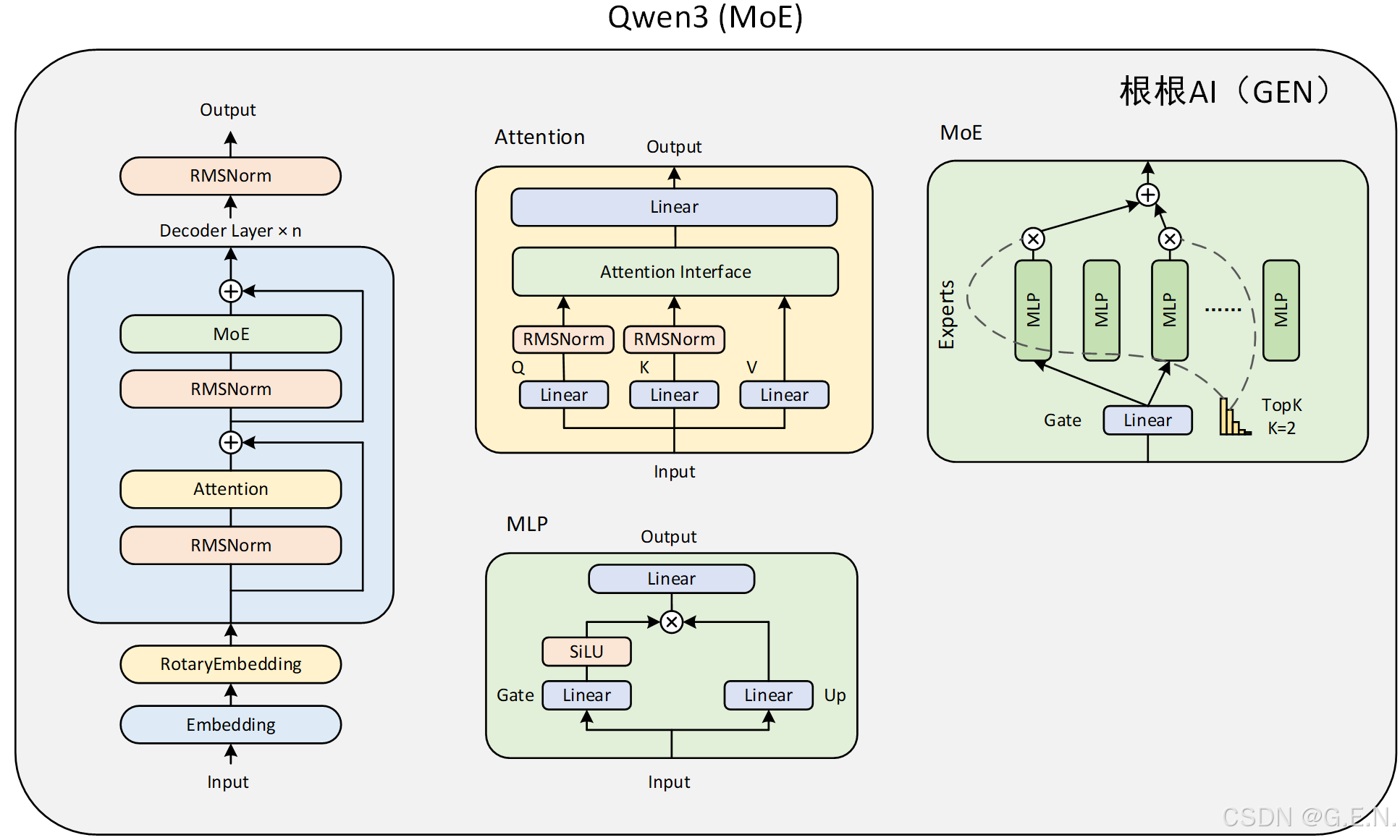
在面试中被问到MoE(Mixture of Experts)模型,通常是考察你对这种先进架构的理解深度。以下是你可以条理清晰地回答的要点,涵盖了MoE的特点、优缺点,以及与稠密模型(Dense Model)的对比。
MoE模型的特点 (Characteristics of MoE Models)
MoE模型最显著的特点是它的模块化(Modularity)和条件计算(Conditional Computation)。
- 多个专家 (Multiple Experts): MoE模型不是一个单一的、巨大的网络,而是由多个独立的、通常是小型的前馈网络(FFN)组成,我们称之为“专家”。每个专家可以学习处理输入数据的不同方面或模式。
- 门控网络/路由器 (Gating Network/Router): 这是一个单独的子网络,它的职责是接收输入数据,并根据输入内容,动态地决定将数据路由给哪个或哪些专家处理。
- 稀疏激活 (Sparse Activation): 这是MoE的核心特征。与传统模型不同,对于每个输入,门控网络通常只会激活少数(例如,Top-K个)专家来参与计算,而不是所有专家。这使得模型在每次推理或训练步骤中,实际激活的参数量远小于模型的总参数量。
- 条件计算 (Conditional Computation): 模型只针对输入数据的特定部分或类型,有条件地激活相关的专家。这意味着计算路径是动态的,根据输入而变化。
MoE模型的优点 (Advantages of MoE Models)
MoE模型的主要优点源于其稀疏激活和模块化特性:
- 巨大的模型容量 (Massive Model Capacity):
- 在不显著增加计算成本的前提下,MoE模型可以拥有比稠密模型多得多的总参数量。 因为每次只激活一小部分专家,所以尽管模型包含数百亿甚至数万亿参数,但每次前向传播的实际计算量却相对较小。这使得模型能够学习更复杂、更细致的知识和模式。
- 更快的训练速度 (Faster Training Speed):
- 由于每次只激活部分参数,因此每次前向和反向传播的计算量减少,从而显著缩短了模型的训练时间。这使得训练超大型模型变得更加可行。
- 更快的推理速度 (Faster Inference Speed):
- 与训练类似,推理时也只激活部分专家,这使得MoE模型在达到相同性能水平时,通常比同等参数量的稠密模型拥有更快的推理速度。
- 专业化能力 (Specialization Capability):
- 不同的专家可以自然地学习到处理不同类型的数据、任务、语言特性或领域知识。例如,在多语言模型中,不同的专家可能专注于不同的语言;在通用模型中,专家可能专注于语法、语义、事实知识等。
- 可扩展性 (Scalability):
- MoE架构更容易扩展。你可以通过增加专家的数量来线性地增加模型容量,而无需重新设计或从头训练整个模型。
MoE模型与稠密模型的对比 (MoE vs. Dense Models)
稠密模型 (Dense Models)
- 特点:
- 所有参数都参与每次计算。
- 模型容量与计算成本直接挂钩:更大的模型意味着更高的计算和内存需求。
- 优点:
- 结构相对简单,易于理解和实现。
- 在参数量相对较小时,性能表现良好且稳定。
- 缺点:
- 扩展性受限: 要进一步提升性能,通常需要线性地增加模型参数,这会导致训练和推理成本呈指数级增长,最终变得无法承受。
- 计算效率瓶颈: 即使对于简单的输入,也需要激活所有参数,导致不必要的计算。
MoE模型 (MoE Models) 的改变、优点与缺点
MoE对稠密模型的改变 (Changes MoE Introduces)
- 结构性改变: 最主要的变化是将稠密模型中的某些MLP(或FFN)层替换为MoE层。MoE层内部包含了多个专家(通常是小型MLP)和一个门控网络。
- 计算模式改变: 从“全员参与”变为“按需激活”的稀疏计算。
- 参数量与计算量解耦: 模型的总参数量可以非常巨大,但单次计算的活跃参数量可以保持相对较低。
MoE模型的优点 (Advantages of MoE over Dense Models)
- 更高的参数效率: 在相同的计算预算下,MoE模型可以拥有远超稠密模型的总参数量,从而捕获更多的知识。
- 更好的性能-效率权衡: 能够以更低的实际计算成本达到甚至超越更大稠密模型的性能。
- 处理异构数据或任务的潜力: 门控网络可以根据输入的特点,动态选择最合适的专家,使其能够更好地处理多样化的数据分布或复杂任务。
MoE模型的缺点 (Disadvantages of MoE Models)
- 训练复杂性 (Training Complexity):
- 负载均衡问题 (Load Balancing): 门控网络可能会倾向于过度使用某些专家而忽略其他专家,导致“专家饥饿”。需要引入额外的负载均衡损失来鼓励专家之间的均匀分配,这增加了训练的复杂性。
- 梯度路由问题: 门控网络的梯度计算可能比较复杂,需要处理好“谁应该收到梯度”的问题。
- 推理延迟波动 (Inference Latency Variability):
- 如果负载均衡不佳,某些输入可能会激活“热门”专家,导致这些专家成为瓶颈,从而增加推理延迟。
- 基础设施要求高 (High Infrastructure Requirements):
- 尽管每次只激活部分专家,但由于模型总参数量巨大,MoE模型通常需要在分布式系统上进行训练和部署,要求高效的并行计算和数据传输能力(例如,需要将不同专家放置在不同的GPU上)。
- 显存占用高: 即使只激活部分专家,为了存储所有专家的参数,所需的总显存仍然非常大。
- 难以调试和理解 (Harder to Debug and Interpret):
- 由于其动态路由的特性,MoE模型的内部工作机制比稠密模型更难理解和调试。你无法简单地跟踪一个固定的计算路径。
- 批量大小限制 (Batch Size Limitations):
- 为了有效利用硬件和负载均衡,MoE模型通常需要较大的批处理大小,这可能在某些资源受限的环境中成为挑战。
稠密 (Dense) vs. 稀疏 (Sparse)
“稠密” (Dense) 和 “稀疏” (Sparse) 是一对相对的概念,在机器学习和深度学习中尤其重要。它们通常用来描述数据的存储方式、模型的结构或激活模式。
这两个词描述的是数据或结构中非零(或活跃)元素的比例。
- 稠密 (Dense): 意味着数据或结构中的绝大多数元素都是非零或活跃的。所有部分都被使用或占用。
- 比喻: 想象一个挤满了人的演唱会现场,几乎没有空位。这就是“稠密”。
- 稀疏 (Sparse): 意味着数据或结构中的绝大多数元素都是零(或不活跃)的。只有一小部分被使用或占用。
- 比喻: 想象一个空荡荡的图书馆,只有零星几个人在看书。这就是“稀疏”。
稠密矩阵 (Dense Matrix) vs. 稀疏矩阵 (Sparse Matrix)
- 稠密矩阵 (Dense Matrix): 矩阵中大部分元素都是非零的。
- 特点: 存储时需要为每个元素都分配空间,即使是零元素。这在矩阵比较小时效率高。
- 示例:
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
- 稀疏矩阵 (Sparse Matrix): 矩阵中大部分元素都是零。
- 特点: 如果直接存储所有元素,会浪费大量空间。因此,通常会采用特殊的数据结构来只存储非零元素的位置和值,从而节省存储空间并提高计算效率。
- 示例:
[[1, 0, 0, 0],
[0, 5, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 9]]
MoE模型结构
- 示例:
MoEModel(
(input_layer): Linear(in_features=20, out_features=128, bias=True)
(moe_layer): MoELayer(
(experts): ModuleList(
(0-3): 4 x Expert(
(fc1): Linear(in_features=128, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=128, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
)
(gate): Gate(
(fc1): Linear(in_features=128, out_features=64, bias=True)
(fc2): Linear(in_features=64, out_features=4, bias=True)
(activation): ReLU()
(softmax): Softmax(dim=-1)
)
)
(output_layer): Linear(in_features=128, out_features=4, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
) - MoE模型结构中,往往有一个 gate(门控网络)和 一个moe_layer(专家网络)组成。每个专家网络 其实通常就是一个MLP(可能由多个Liner+Norm层组成)。专家的数量越多,MoE模型整体参数越大。
- 但并不是每次都会将全部专家的参数激活,Qwen、DS等大模型中,每次激活2个。也就是说由gate控制 激活 N 个专家中的 2个。
- gate层的结果可能是:tensor([0.0113, 0.0303, 0.9145, 0.0439], device=’cuda:0’)可以看出,第3、4个专家权重大,因此激活 第3、4个专家网络。
MoE中的门控和LSTM的门控有什么区别?
MoE中的门控机制和LSTM中的门控机制虽然都叫“门控”,但它们的目的和工作方式有着本质的区别。
1. MoE中的门控 (Gating in MoE)
- 目的:路由选择和专家激活。 它的主要任务是根据输入数据的特征,决定将数据路由(route)给哪个或哪些专家进行处理,或者如何加权(weight)不同专家的输出。
- 工作方式:
- 输入: 门控网络接收模型的当前表示(通常是前一层或输入的隐藏状态)。
- 输出: 它会输出一组分数或概率分布(通常通过Softmax),对应于每个专家的选择偏好。例如,如果
top-k路由被使用(如Mixtral 8x7B中),它会选择得分最高的k个专家。 - 决策: 根据这些分数,数据被发送到选定的专家,或者专家的输出被这些分数加权求和。
- 比喻: 就像一个交通警察或分诊台。它观察来往的车辆(数据),然后决定把它们引导到哪条车道或哪个诊室(专家),以最高效地处理它们。它关注的是“谁来处理这个问题?”
2. LSTM中的门控 (Gating in LSTM)
- 目的:信息流控制和长期依赖学习。 它的主要任务是控制信息在时间步上的流动,包括哪些信息应该被“记住”(添加到细胞状态),哪些信息应该被“遗忘”,以及哪些信息应该被“输出”。
- 工作方式:
- 输入: LSTM的门控机制接收当前时间步的输入和上一时间步的隐藏状态。
- 输出: 它内部有三个核心门:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。这些门通常通过sigmoid激活函数生成介于0和1之间的值,作为“开”或“关”的信号。
- 决策:
- 遗忘门: 决定细胞状态中有多少信息应该被保留(或遗忘)。
- 输入门: 决定当前输入有多少信息应该被添加到细胞状态。
- 输出门: 决定当前细胞状态有多少信息应该被输出到隐藏状态。
- 比喻: 就像一个水闸控制器。它根据当前的水量和需求(输入和状态),精确地控制水流(信息流)的进入、保留和流出。它关注的是“如何管理和更新内部信息?”
MoE模型的训练方式与Dense模型一致,从零开始训练 (Training from Scratch)
这是最直接也是最常见的方法。
- 模型构建: 在模型设计阶段,你就已经明确了哪些层将是MoE层(例如,在Transformer的FFN层位置)。门控网络和专家网络都会被初始化。
- 联合优化: 门控网络和所有的专家网络会同时进行端到端的训练。这意味着在反向传播过程中,梯度会同时流经门控网络和被激活的专家。
- 门控网络的学习: 门控网络会学习如何根据输入有效地将数据路由到最合适的专家。同时,每个专家也会学习如何处理它被分配到的那部分数据。
- 负载均衡 (Load Balancing): 在训练MoE模型时,一个非常重要的问题是负载均衡。如果某些专家被过度使用,而另一些专家几乎不被使用,模型性能会受损。因此,通常会引入一个“负载均衡损失”(Load Balancing Loss),它会鼓励门控网络将输入数据均匀地分配给不同的专家,防止“专家饥饿”或“专家过载”。这使得所有专家都有机会学习。
- 比喻: 就像一个团队,你希望每个成员都能发挥作用,而不是让少数人累死,多数人闲着。负载均衡就是确保每个专家都有活干。
如何避免MoE模型训练初期的“专家饥饿”问题
相关策略
门控网络均匀初始化: 门控网络的权重应被初始化,使得在训练初期,它对所有专家都给出大致相同的路由分数。这避免了在训练开始时就出现偏向。
门控网络引入噪声: 可以加入少量噪声,允许门控网络探索不同的路由路径。
Gemini说的 负载均衡损失方法
- 个人理解:在 NLP任务的主 Loss之外,引入辅助Loss,与主Loss是加权的关系。
- 总Loss = 主loss + a*辅助loss,这里a是超参,通常占比较小,且逐渐减少。
- 这个辅助loss主要由 每个专家在某一批次中的被门控网络分配的分数 和 生成分数后专家真正被选中的次数组成(点积计算)。因此,如果某些专家频繁被选中,则Loss很高,反之则低。(可以想象 1、2专家分数高,但却以极低概率选择了3、4,那这样loss就是0)
在Top-K路由中,门控网络会选择得分最高的K个专家来处理输入,这使得负载均衡变得尤为重要,因为很容易出现少数专家被过度使用,而大部分专家“挨饿”的情况。在Top-K路由中,负载均衡损失(Load Balancing Loss)的目标是确保每个专家在批次中被选中的次数大致相等。最常用的方法是辅助损失(Auxiliary Loss),它旨在鼓励专家激活的均匀分布。
核心思想
辅助损失的原理是最小化两个量的乘积:
- 专家的重要性(Expert Importance): 每个专家在整个批次中被门控网络赋予的平均路由分数。
- 专家被选中的平均负载(Expert Load): 每个专家在整个批次中实际被选中的次数占总路由次数的比例。
直观地讲,我们希望这两者是解耦的。也就是说,一个专家被赋予的平均分数不应该与其被选中的频率强相关。如果所有专家都被均匀地选中,那么这个损失就会很小。


