正文
FlashAttention和pageattention属于工程层面的技术,而不是某种注意力。
以下注意力是模型结构、数学层面的。
传统注意力
传统注意力机制最早被提出用于 机器翻译,它的核心思想是 聚焦于输入序列中的不同部分。
给定查询(Query)和键值对(Key-Value),计算 相似度(一般使用点积):
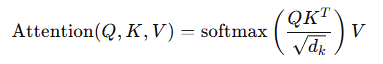
通过 softmax 操作将相似度转换为权重,然后用这些权重加权求和得到最终的输出。
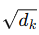 是缩放因子, 防止值过大导致梯度消失或梯度爆炸。
是缩放因子, 防止值过大导致梯度消失或梯度爆炸。
为什么要进行缩放?梯度消失、爆炸的原因?
点积的结果可能会非常大。假设查询 Q 和键 K的维度很大,点积会产生一个 很大的数值,然后经过 softmax 进行归一化。由于 softmax 对大值非常敏感,计算出来的概率分布可能会非常 不平衡,即某些位置的权重几乎为 0,而其他位置的权重几乎为 1。这样会导致模型训练时 梯度爆炸或梯度消失 的问题。
复杂度O(N²)
多头注意力
工作原理:
- 将查询、键、值分别 线性映射 为多个子空间。
- 对每个子空间计算独立的注意力,并最终将所有头的输出拼接在一起,再经过 线性变换。
- 这样可以在不同的空间中 捕捉不同的关系,从而增加模型的表现力。
关键点:
- 头数 (Heads):设置多个头数可以提高模型的表示能力,但头数过多也可能导致计算开销过大。
- 维度分配:每个头对应的维度是 d_model/h,其中 h 是头数,保证每个头处理的维度相同。
- pytorch中的MultiheadAttention 嵌入维度必须能够被头数整除
- 如果嵌入维度无法被头数整除,就无法保证每个头得到相等长度的输入,这会导致注意力计算的结果产生偏差。
- 减少计算量。当嵌入维度能够被头数整除时,每个头得到的输入维度相等,这样可以方便地进行并行计算。而如果嵌入维度无法被头数整除,就需要进行额外的处理来适配不同长度的输入,这会增加计算的复杂性和运行时间。
交叉注意力
交叉注意力允许一个序列(或信息流)中的元素关注另一个不同序列中的元素,从而实现两个序列之间的信息对齐和融合。
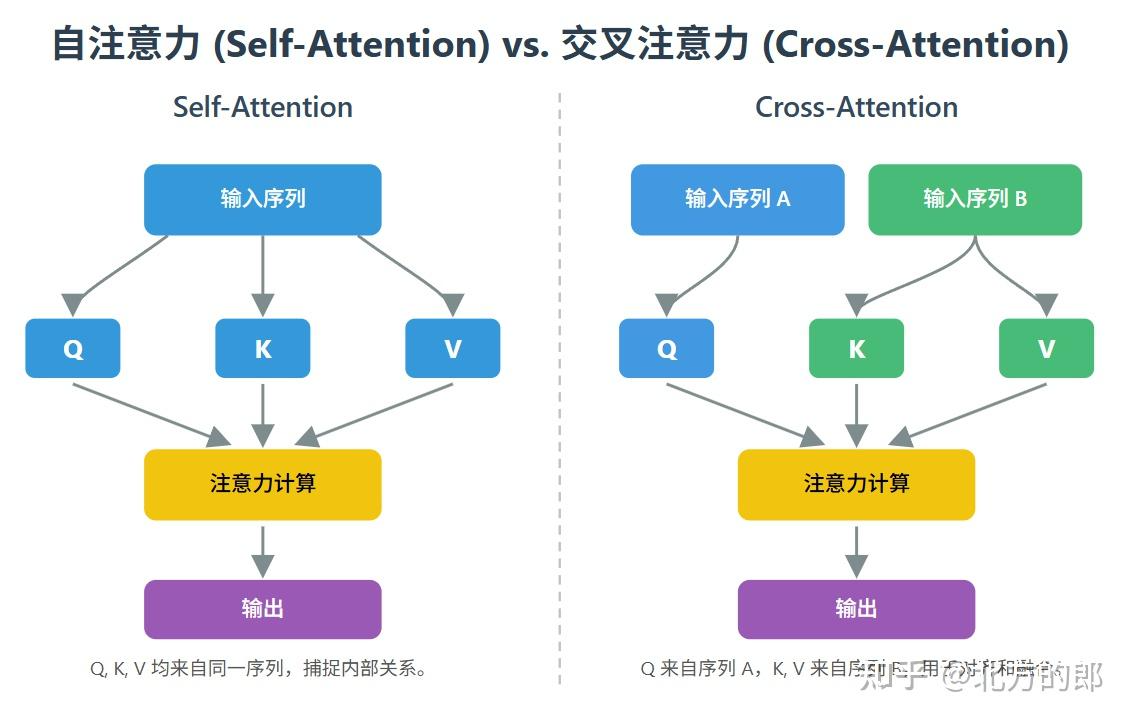
交叉注意力的独特能力使其在需要处理和对齐多种信息流的任务中大放异彩。
应用:
机器翻译:它帮助模型在生成目标语言的每一个词时,都能关注到源语言句子中最相关的部分,确保翻译的准确性和流畅性
图像描述生成:模型可以利用交叉注意力,让代表文本生成状态的 Q 去关注图像特征(K 和 V),从而生成与图像内容高度相关的描述。
视觉问答系统:非对称交叉模态注意力网络,通过图像引导的注意力和问题引导的注意力来改善多模态信息的交互,从而在提供的医学影像和问题文本中找到最相关的部分来提取答案。
线性注意力
传统的注意力机制,如Transformer中的自注意力,其计算复杂度是 O(n²),其中 n 是序列的长度。
- 点积计算:
- 假设输入序列长度为
n,那么每个注意力头要计算n × n(Q·K)的相似度矩阵。 - 由于计算需要存储和操作这个
n²的矩阵,内存和计算成本随着n的增大而急剧增加。
- 假设输入序列长度为
线性注意力的目标是通过核方法,优化传统注意力计算中的点积过程,将计算复杂度从 O(n²) 降低到 O(n),使得它在处理长序列时更高效。
通常会通过以下两种方式来实现:
- 核函数(Kernel Function):通过将点积注意力计算转换为一种逐步累加的形式,利用核函数将复杂度降低为线性。
- 重新排列计算顺序:通过改变计算顺序,将计算复杂度优化到线性,避免了大规模矩阵乘法操作。
核心思想:在传统的注意力机制中,查询(Query)与键(Key)通过点积计算相似度,然后通过Softmax生成权重。但在线性注意力中,直接对点积计算进行优化,使用核方法来避免直接计算每一对查询-键的点积。
- 核方法通过近似计算来降低计算复杂度。常用的核函数有:
- 高斯核(Gaussian Kernel):例如
exp(-||Q - K||² / 2σ²),将查询和键之间的点积转化为某种距离的核计算。 - 正弦核(Sine Kernel):通过将正弦函数应用于查询和键的差异,来近似计算注意力权重。
- 高斯核(Gaussian Kernel):例如
通过引入核函数,可以将传统的 点积 操作转化为 线性 计算,从而避免了二次方的计算复杂度。
优点:
- 计算复杂度:最大优点是将复杂度从 O(n²) 降低到 O(n),使得它能够处理更长的序列,尤其是在长文本和长时间序列的任务中非常有用。
- 内存优化:由于计算不再需要存储大的相似度矩阵,内存开销显著降低,适合大规模模型和长序列。
缺点:
- 近似精度:通过核函数近似计算相似度可能会引入一定的误差,尤其是在复杂任务或需要高度精确计算的场景中,可能不如传统的注意力机制精确。
- 实现复杂度:核方法的设计和实现相对复杂,需要根据任务和硬件选择合适的核函数,并调优相关参数。
- 为什么要使用线性注意力?
重点是提升长序列处理效率,避免传统注意力在长序列时的计算和内存瓶颈。 - 线性注意力的核心思想是什么?
通过使用核方法(例如高斯核、正弦核)近似计算查询和键之间的相似度,避免了计算点积的二次方复杂度。 - 线性注意力是否总是比传统注意力好?
不是。线性注意力通过近似计算,虽然计算效率提升,但在某些任务中可能会牺牲一定的精度,尤其是当核函数设计不当时。 - 线性注意力的实现难度有哪些?
需要对核函数有较深理解,且在实践中选择合适的核函数非常重要。不同的任务可能需要不同类型的核函数来获得最佳效果。 - **既然线性注意力这么好,为什么之前的方法要用点积计算而不是核方法? **
- 为什么要使用线性注意力?
设计时的目标不同:传统的注意力机制(例如Transformer中的自注意力)最初的设计目标是信息交互和建模关系,而核方法的引入主要是为了在长序列上减少计算量。最早提出的Transformer并没有长序列处理的需求。
** 使用核方法会带来一定的近似误差。**