正文
mLSTM和sLSTM是xLSTM的组成部分,都是LSTM的高级变体算法。mLSTM引入了矩阵存储单元以及用于键值对存储的协方差更新机制,这大大增加了模型的内存容量。门控机制与 covariance update 规则协同工作,以有效地管理内存更新。通过删除hidden-to-hidden connections,可以并行执行 mLSTM 操作,从而加快训练和推理过程。
本文采用的mLSTM结构如图所示。
mLSTM的结构如图所示。mLSTM将记忆单元中的记忆细胞从标量扩展到到矩阵,从而提高需要理解序列任务的性能。mLSTM块的输入在经过投影因子为2的投影后,分别作为外部输出门和mLSTM记忆单元的输入。对于记忆单元的输入,采用kernel_size为4的因果卷积进行特征提取和四个对角块的块对角投影矩阵进行线性变换,得到q、k、v,其中v跳过了之前的卷积层,由记忆单元的输入进行线性变换得到。隐状态在输出后进行组归一化,并与可学习跳跃输入(LSkip)相加,在经过下投影后,与残差连接进行相加后输出。
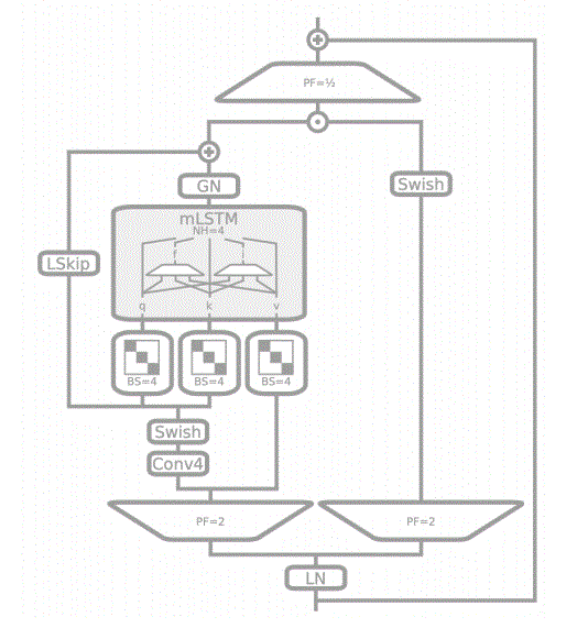
在mLSTM的构建中,kernel_size为4的causalConv被用于处理输入数据。causalConv只关注当前和过去的操作,不会获取未来的信息,使其在处理时序数据时不违反时间的因果关系,这对于序列预测任务非常重要。
然而,因果卷积的感受野取决于卷积核的大小,虽然可以通过堆叠多个卷积层来扩大感受野,但每一层卷积的本质仍然是在捕获局部特征,同时会增加过多的计算量,因此在长距离依赖问题中mLSTM仍然具有局限性。
为了使模型更好地捕捉和利用这种时序信息,我们提出一种改进的mLSTM模型名为CAmLSTM。通过引入因果注意力机制替换掉causalConv,重新构建mLSTM块。
因果注意力机制是对注意力机制的一种改进,通过mask掉未来的信息,确保模型在长距离依赖问题中的有效性。
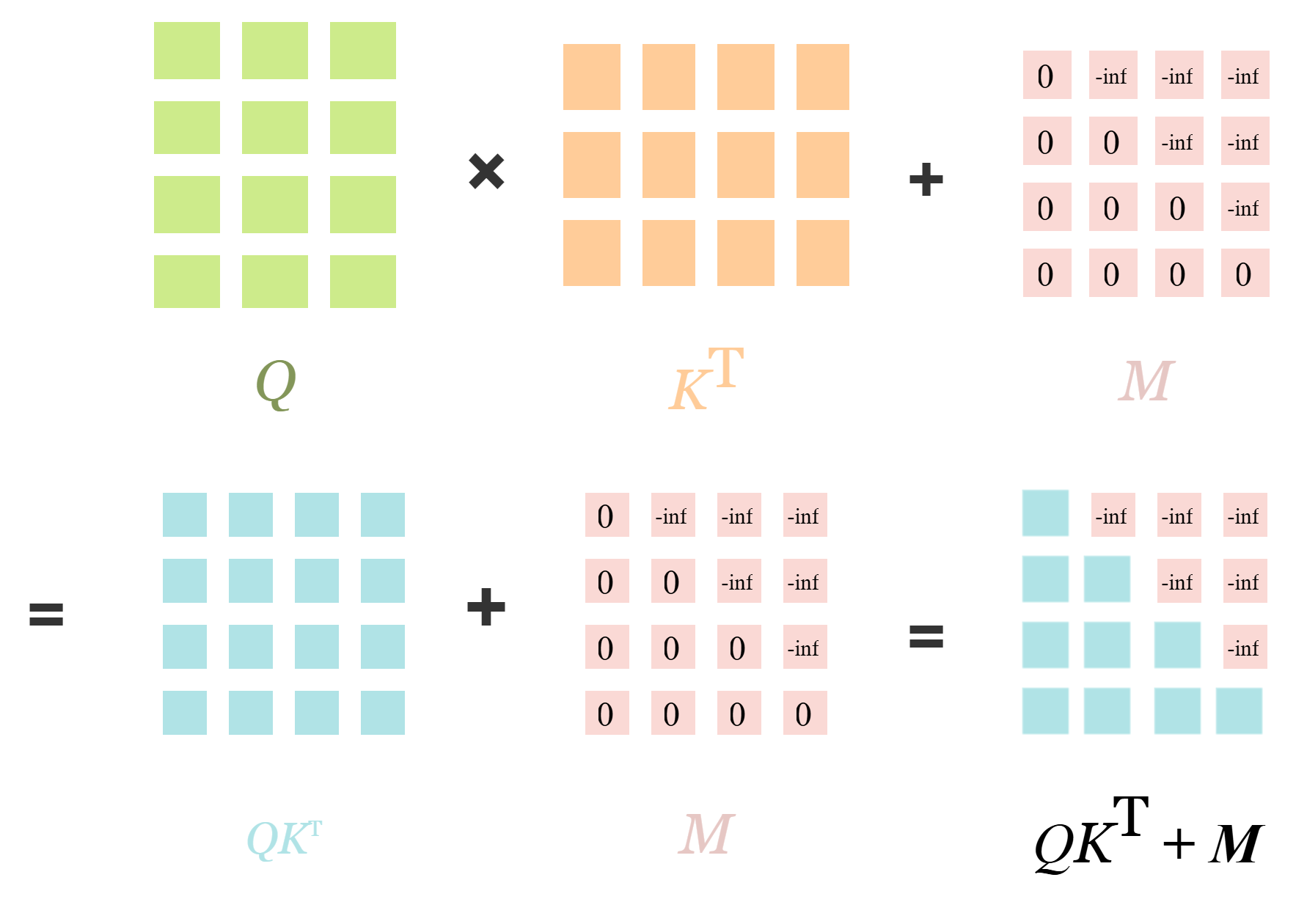
如图所示,在计算注意力权重时,因果注意力通常对注意力权重矩阵QKt添加一个掩码矩阵M,矩阵M满足公式:
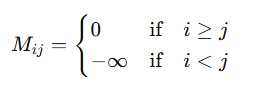
矩阵M的上三角部分(未来时刻)为负无穷,下三角部分(过去时刻)为0。在与原始权重矩阵QKt进行相加后得到新的注意力权重矩阵,如公式所示。
QKt_masked = QKt + M
矩阵QKt_masked的下三角部分仍然为原始权重,而上三角部分变为负无穷大(表示模型获取该部分信息)。通过这种掩码操作,在Softmax计算后,上三角部分权重变为0,这意味着模型只能关注到过去及当前时刻的时间步信息。Softmax的计算公式如下所示。
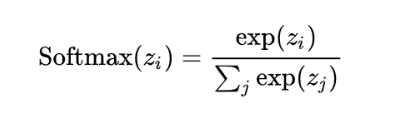
(画公式图)
最终,mLSTM的计算过程如下所示:

本文采用CAmLSTM作为MBLB模块的最后一层。下一节,将介绍RBLB模块。