正文
存入 KV cache 的是什么内容?
KV cache 顾名思义,存储的是 Key (键) 和 Value (值) 向量。
在 Transformer 模型的自注意力(Self-Attention)机制中,为了计算每个 token 的输出,需要用到三个向量:Query (查询)、Key (键) 和 Value (值)。这三个向量是通过将输入 token 的 Embedding 向量分别乘以三个不同的权重矩阵 WQ,WK,WV 得到的。
在生成新 token 的过程中(即自回归推理),模型会逐个生成 token。对于每一个新生成的 token,它需要和之前所有已生成的 token 计算注意力。
- 没有 KV cache 时:每生成一个新 token,模型都需要重新计算所有之前 token 的 Key 和 Value 向量,这会造成大量的重复计算。
- 有了 KV cache 后:模型会把每一步计算得到的 Key 和 Value 向量都缓存(存储)起来。当生成下一个 token 时,模型只需要计算这个新 token 自己的 Key 和 Value,然后将其与之前缓存的所有 Key 和 Value 拼接起来,就可以直接用于注意力计算了。这样就避免了对历史 token 的重复计算,大大提升了推理速度。
个人理解
自回归模型在推理的过程中,是以token为单位进行推理。在推理某个token时,需要计算利用该token之前的所有token进行计算。
在self-attention中,每个token都要经历Attention的计算。即:
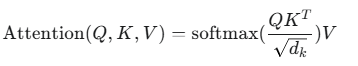
假设我们要生成一个 3 个 token 的序列(没有kvcache):[token_1, token_2, token_3]。
- 生成 **
**token_1**:**- 输入:
[token_1] - 计算
Q_1,K_1,V_1。 - 计算
token_1的自注意力输出:Attention(Q_1, K_1, V_1)。
- 输入:
- 生成 **
**token_2**:**- 输入:
[token_1, token_2] - 模型需要计算
token_2的输出。为了计算这个,它需要获取token_2的Q向量,以及所有历史 token(即token_1和token_2)的K和V向量。 - 问题来了: 如果没有 KV cache,模型会再次从头开始处理整个输入序列
[token_1, token_2]。 - 它会重新计算
Q_1, K_1, V_1。 - 然后计算
Q_2, K_2, V_2。 - 最后计算
token_2的自注意力输出:Attention([Q_1, Q_2], [K_1, K_2], [V_1, V_2])。 - 注意,这里的
K_1, V_1向量是重新计算的。
- 输入:
- 生成 **
**token_3**:**- 输入:
[token_1, token_2, token_3] - 模型会再次从头开始处理整个序列
[token_1, token_2, token_3]。 - 它会重新计算
Q_1, K_1, V_1。 - 重新计算
Q_2, K_2, V_2。 - 然后计算
Q_3, K_3, V_3。 - 最后计算
token_3的自注意力输出:Attention([Q_1, Q_2, Q_3], [K_1, K_2, K_3], [V_1, V_2, V_3])。 - 这里的
K_1, V_1和K_2, V_2向量都是重复计算的。
- 输入:
在推理时,如果要生存个token,那么 token1会被计算3次,token2计算2次,token3计算1次,一共要计算6次。
如果进行kvcache,前面的每个token只需计算1次,每次只将当前token的计算结果 追加到前面的token中即可,不需要重复计算。