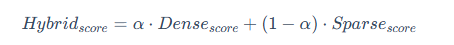正文
主要背景、目标:解决单一检索技术的局限性。例如,关键词检索无法理解语义,而向量检索则可能忽略掉必须精确匹配的关键词(如产品型号、函数名等)。
混合检索旨在同时利用稀疏向量的精确性和密集向量的泛化性,以应对复杂多变的搜索需求。
稀疏向量如何使用?
类似[0,0,2,3,0,0]这样的向量称为稀疏向量。
通常通过bm25等统计模型进行提取,反应出每个词在文中出现的频次、频率等统计信息,可以称为关键词权重。结果可能为:{‘今天’:0.01545,”晴天”:0.5212,”不适合”:0.3258,”滑雪”:0.15793}
使用方法1:
- 在完成chunk的切分后,预先使用bm25对所有chunk进行稀疏向量提取。(离线进行)
- 设置提取的关键词数量k,只提取分数最高的前k个关键词。保存为k维向量(不足补0)。
- 随后,在用户问答时,将query用同样方式进行提取,得到维度相同的向量。(在线进行)
- 依次计算两者的余弦相似度分数。根据分数排序召回。
使用方法2:
- 在完成chunk的切分后,预先使用bm25对所有chunk进行稀疏向量提取,不需要转为向量矩阵。(离线进行)
- 在用户问答阶段,使用bm25对用户query进行稀疏向量提取,不需要转为向量矩阵,得到query_sparse(在线进行)
- 遍历query_sparse中全部的key(对应为关键词),在每个chunk中分别计算每个key的对应的bm25权重分数,并汇总每个chunk的总得分。
- 将chunk按总得分排序召回。
方法2举例:query:今天天气挺好,适合去滑雪
chunk1:10月13日是晴朗的一天,适合散步。
chunk2:天气情况良好,适合去雪山滑雪。
query_sparse:
{
“天气”: 0.85, “滑雪”: 0.90, “适合”: 0.60, “今天”: 0.55, “挺好”: 0.70, “去”: 0.20
}
chunk1_sparse:
{
“10月13日”: 0.80, “晴朗”: 0.85, “一天”: 0.40, “适合”: 0.60, “散步”: 0.90, “是”: 0.10
}
chunk2_sparse:
{
“天气”: 0.80, “情况”: 0.55, “良好”: 0.70, “适合”: 0.60, “去”: 0.20, “雪山”: 0.85, “滑雪”: 0.90
}
每个chunk1的最终分数为query_sparse中出现的每个key在chunk1_sparse和chunk2_sparse中对应的分数之和。(未出现的key,按0算)chunk1_total_score=0.60(适合)=0.6chunk1_total_score=0.80(天气)+0.60(适合)+0.20(去)+0.90(滑雪)=2.5
最后按分数排序。
倒数排序融合 (Reciprocal Rank Fusion, RRF)
RRF 不关心不同检索系统的原始得分,只关心每个文档在各自结果集中的排名。其思想是:一个文档在不同检索系统中的排名越靠前,它的最终得分就越高。
其计分公式为:

- RRFscore(d): 文档 d 的最终得分。
- k: 检索系统数量。
- ranki(d): 文档 d 在第 i 个系统中的排名。
- c: 平滑常数(通常为 60)。
RRF个人理解:
一切检索之前做的”分数融合”,无论是简单的线性相加,或者复杂公式得到的最终分数,都是以召回某个chunk为最终目的的。
RRF更像是Rerank做的事情。
RRF的实现可以使用 稀疏向量和稠密向量 构建2套检索系统,然后用RRF对根据某个chunk在不同系统中排名,进行综合排序,类似重排。
加权线性组合
这种方法需要先将不同检索系统的得分进行归一化(例如,统一到 0-1 区间),然后通过一个权重参数 α 来进行线性组合。