正文
✅ 白盒蒸馏(White-box Distillation):你能访问教师模型的内部输出(logits 概率分布)。
✅ 黑盒蒸馏(Black-box Distillation):你只能拿到教师模型生成的文本(答案字符串),不能访问 logits。 白盒:开源模型
黑盒:毕源模型
⚙️ 黑盒蒸馏训练——简单、低成本、可用范围广(基本任何模型都可以做)
和SFT基本一致,找一个由高级LLM生成的数据集,按SFT格式存储,让小模型再训一次,就属于黑盒知识整理。例如 LaMini-LM 这项工作创建了一组 258 万条指令,并采用 GPT-3.5 Turbo 来生成对这些指令的响应。随后,它使用这些指令作为基础来微调一系列学生模型。
黑盒蒸馏也被认为是一种很有前途的工具,可以将思维链 (CoT) 的能力从较大的模型转移到较小的模型。
流程:
- 教师模型(如 DeepSeek-R1、GPT-4)生成高质量样本;
- 把这些样本保存成 JSONL 格式;
- 学生模型用 SFT 模式模仿这些文本;
- 不需要教师模型的参与。
⚙️ 白盒蒸馏训练
学生模型 **不仅学习输出结果,还学习 **教师模型 的** logits、attention、隐藏层向量**等 。
因此需要确保教师模型属于开源模型(开放权重)。
- logits(输出层的概率分布)
- hidden states(每层隐藏层输出)
- attention maps(注意力矩阵)
一般以batch为单位,进行batch内计算。
| 常见的蒸馏损失 | 符号 | 含义 |
|---|---|---|
| Soft Target Loss | ( L_{logit} ) | 让学生匹配教师的输出分布(KL散度) |
| Feature Loss | ( L_{hidden} ) | 匹配隐藏层向量(MSE) |
| Attention Loss | ( L_{attn} ) | 匹配注意力权重矩阵(MSE) |
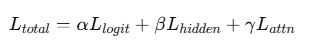
在白盒蒸馏中,模型参数、结构异构怎么办?
| item | 是否必须相同 | 原因 | | — | — | — | | 参数数量(hidden size, layers) | ❌ 不必须相同 | 学生模型往往更小(例如 Teacher=70B,Student=7B) | | 网络结构类型(Transformer架构) | ✅ 必须相同或兼容 | 才能有可映射的层、注意力结构、hidden states | | 层数(num_layers) | ⚠️ 不同可以,但要做层对齐(layer mapping) | 否则无法逐层匹配 hidden state | | 词表(tokenizer) | ⚠️ 尽量相同 | 不同词表会导致 embedding 对齐困难 | | 激活函数、位置编码等 | ✅ 最好一致 | 否则中间层空间差异太大,MSE损失无意义 |
知识蒸馏的核心目标是:让学生“模仿”教师的输出行为或内部特征分布。因此只要学习中间层特征,所以需要结构相似但不必完全相同。
如果教师和学生层数不同,通常采用层映射策略(Layer Mapping):
| 教师层索引 | 学生层索引 |
|---|---|
| 0 | 0 |
| 2 | 1 |
| 5 | 2 |
| 8 | 3 |
| … | … |
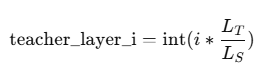
如果两模型的底层机制不同,比如:
- 一个用 RoPE(旋转位置编码),一个用 ALiBi;
- 一个用 SwiGLU,一个用 GeLU;
这些差异会导致 hidden state 的分布差异极大。
📉 直接用 MSE 蒸馏会导致“无意义的匹配”,因此:
- 解决方案:加一个小投影层(adapter projection)把教师向量映射到学生空间。