正文
本章涉及内容:BPE、LoRA
BPE(Byte Pair Encoding) 字节对编码参考:BPE(Byte Pair Encoding,字节对编码) - 朴素贝叶斯 - 博客园 (cnblogs.com)
一种叫作BPE(Byte Pair Encoding,字节对编码)的子词切分技术。
一般对于英语这种语言,尽管词语之间已经有了空格分隔符,但是英语的单词往往具有复杂的词形变换,如果只是用空格进行切分,会导致数据稀疏问题。
传统的处理方法根据语言学规则,引入词形还原(Lemmatization)或词干提取(Stemming),提取出单词的词根,从而一定程度上缓解了数据稀疏的问题。比如’fishing”,’fished”,’fish”和’fisher” 为同一个词根’fish”。但是需要人工编写大量的规则,同时不容易扩展到新的领域。因此,基于统计的无监督子词(Subword)切分任务应运而生,并在现代的预训练模型上大量使用。(子词切分是指将一个单词切分为若干连续的片段。本文重点介绍BPE技术。)
BPE的步骤如下:
初始化语料库
将语料库中每个单词切分为字符作为子词,并在单词结尾添加</w>
用切分的子词构成初始子词词表
在语料库中统计单词内相邻子词对的频次
合并频次最高的子词对,合并成新的子词,并将新的子词加入到子词词表
重复步骤4和5直到进行了设定的合并次数或达到了设定的子词词表大小
假设语料库中存在4个单词,并且我们已经统计了每个单词对应的频次。每个单词结尾增加了一个</w>字符,同时将每个单词切分成独立的字符构成子词。
初始语料库为:
{‘l o w </w>’ : 5, ‘l o w e r </w>’ : 2, ‘n e w e s t </w>‘:6, ‘w i d e s t </w>‘:3}
初始化的子词词表为4个单词包含的全部字符:
{‘l’,’o’, ‘w’, ‘</w>’, ‘e’, ‘r’, ‘n’, ‘s’, ‘t’, ‘i’, ‘d’}
然后统计单词内相邻的两个子词的频次:
{‘lo’: 7, ‘ow’: 7, ‘w</w>’: 5, ‘we’: 8, ‘er’: 2, ‘r</w>’: 2, ‘ne’: 6, ‘ew’: 6, ‘es’: 9, ‘st’: 9, ‘t</w>’: 9, ‘wi’: 3, ‘id’: 3, ‘de’: 3}
并选取频次最高的子词对’e’和’s’,合并成新的子词’es’。其中es在newest</w>中出现了6次,在widest</w>总出现了3次,一共是9次。但是可以看到,其中st和 t </w>也是出现了9次,这里选取的是第一个,es。
然后加入子词词表中,并将语料库中不再存在的子词 s 从子词词表中删除。此时,语料库变为:
{‘l o w </w>’ : 5, ‘l o w e r </w>’ : 2,’n e w es t </w>‘:6, ‘w i d es t </w>‘:3}
子词词表:
{‘l’,’o’, ‘w’, ‘</w>’, ‘e’, ‘r’, ‘n’, ‘t’, ‘i’, ‘d’, ‘es’}
然后,合并下一个子词对es和 t ,新的语料库变成了:
{‘l o w </w>’ : 5, ‘l o w e r </w>’ : 2,’n e w est </w>‘:6, ‘w i d est </w>‘:3}
子词词表(删除了语料库中不存在的 t ):
{‘l’,’o’, ‘w’, ‘</w>’, ‘e’, ‘r’, ‘n’, ‘i’, ‘d’, ‘est’}
重复以上过程,直到子词词表大小达到一个期望的词表大小为止。
最终得到的语料库为:
{‘low</w>’: 5, ‘low e r </w>’: 2, ‘newest</w>’: 6, ‘wi d est</w>’: 3}
子词词表为:
{‘low</w>’, ‘low’, ‘e’, ‘r’, ‘</w>’, ‘newest</w>’, ‘wi’, ‘d’, ‘est</w>’}
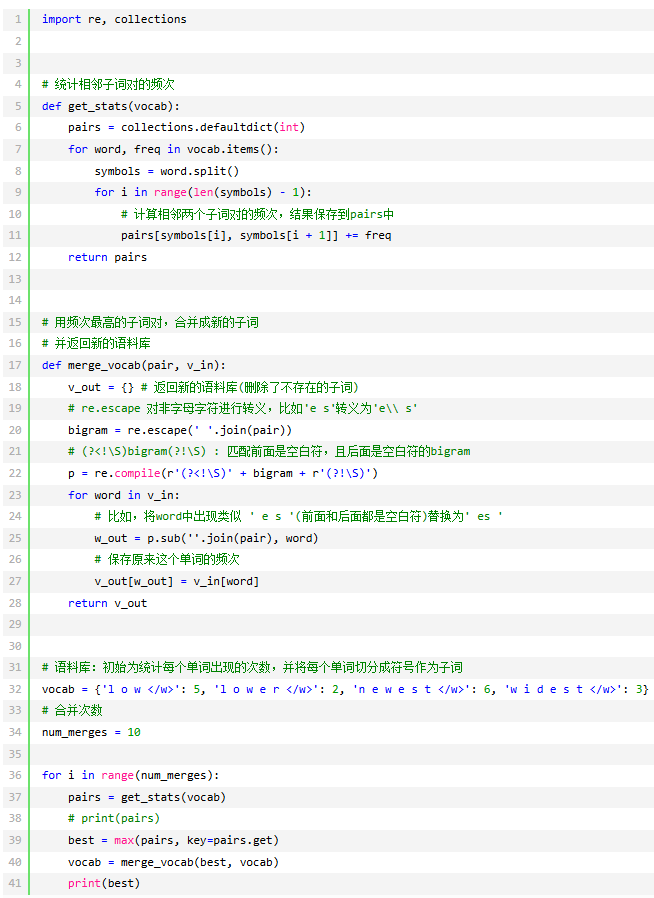
源码:
LoRA
在模型中某些关键层(如全连接层,注意力层)的权重矩阵 W分解为低秩表示。
通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
LoRA的实现思想很简单,就是冻结一个预训练模型的矩阵参数,并选择用A和B矩阵来替代,在下游任务时只更新A和B。
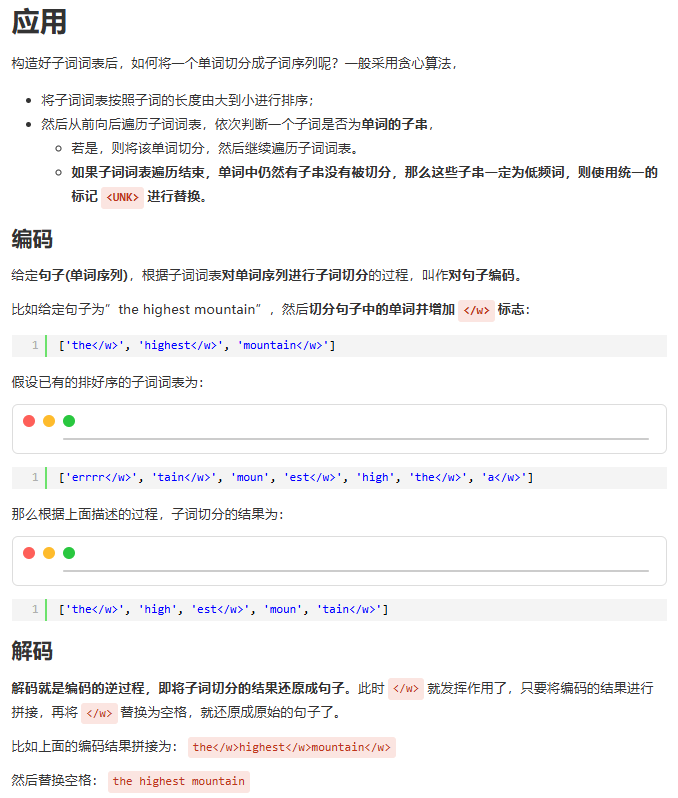
LoRA的思路:
-
在原模型的关键层()旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量;
-
训练时,原模型权重固定,只训练降维矩阵A和升维矩阵B;
-
推理时,可将BA矩阵(低秩矩阵)加到原参数上,不引入额外的推理延迟;
-
初始化,A采用高斯分布初始化,B初始化为全0,保证训练开始时旁路为0矩阵;
-
可插拔式的切换任务,当前任务W0+B1A1,将lora部分减掉,换成B2A2,即可实现任务切换
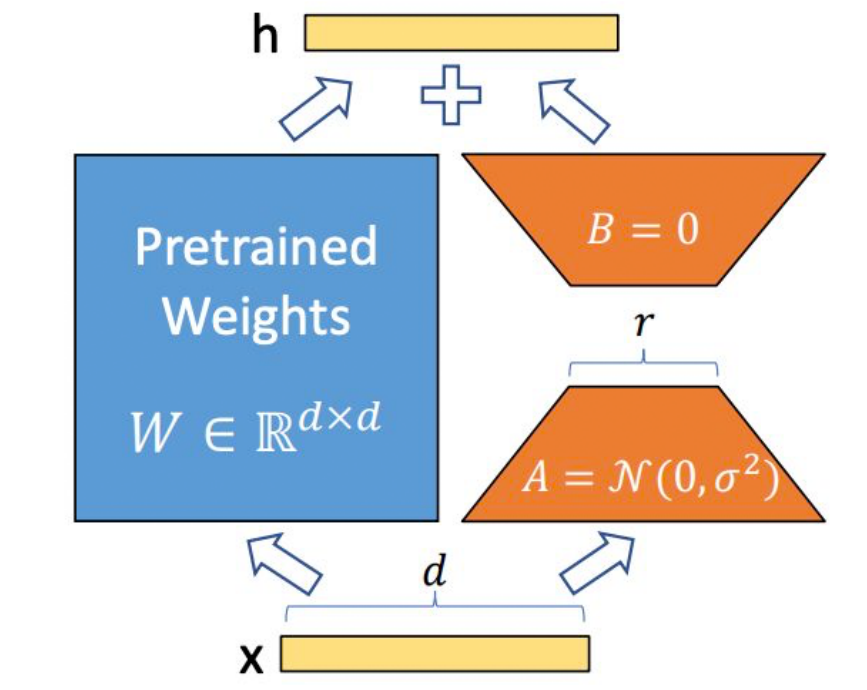
Lora的矩阵怎么初始化?为什么要初始化为全0?
矩阵B被初始化为0,而矩阵A正常高斯初始化。
如果B,A全都初始化为0,那么缺点与深度网络全0初始化一样,很容易导致梯度消失(因为此时初始所有神经元的功能都是等价的)。如果B,A全部高斯初始化,那么在网络训练刚开始就会有概率为得到一个过大的偏移值Δ W 从而引入太多噪声,导致难以收敛。
因此,一部分初始为0,一部分正常初始化是为了在训练开始时维持网络的原有输出(初始偏移为0),但同时也保证在真正开始学习后能够更好的收敛
LoRA权重合并:将训练好的低秩矩阵(B*A)+原模型权重合并(相加),计算出新的权重。
LoRA 微调优点是什么?
-
一个中心模型服务多个下游任务,节省参数存储量
-
推理阶段不引入额外计算量(不额外增加推理时间)
-
与其它参数高效微调方法正交,可有效组合
-
训练任务比较稳定,效果比较好
-
LoRA 几乎不添加任何推理延迟,因为适配器权重可以与基本模型合并
LoRA这种微调方法和全参数比起来有什么劣势吗?LoRA参数参数:Rank 如何选取?
Rank的取值效果上Rank在4-8之间最好,再高并没有效果提升。指令微调上根据指令分布的广度,Rank选择需要在8以上的取值进行测试。
参数:alpha参如何选取?
alpha其实是个缩放参数,本质和learning rate相同,所以默认让alpha=rank,只调整lr,简化超参。
LoRA 高效微调 如何避免过拟合?
减小r(秩)或增加数据集大小可以减少过拟合。还可以增加优化器的权重衰减率或LoRA层的dropout值。
QLoRA设计思路:
-
使用一种新颖的高精度技术将预训练模型量化为 4 bit;
-
添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
特点:
显存要求低,但速度慢于LoRA
微调大模型时, 优化器如何选择?
除了Adam和AdamW,其他优化器如Sophia也值得研究,它使用梯度曲率而非方差进行归一化,可能提高训练效率和模型性能。