正文
个人理解:
我理解Q-learning其实就是绘制一张Q表格,表格的列数是智能体能够执行的动作数(例如动作为前、后则为2),表格的行数是状态空间的数量(例如状态空间为2*8则为16)。Q表格中每一个单元格的内容,对应当智能体处于某个位置时 执行某个动作的 预期累积奖励 。
- 位置与状态 属于同一概念。
- 这里不涉及深度学习,只是利用智能体按采用结果,走不同路 得到的奖励,进行迭代更新Qtable。
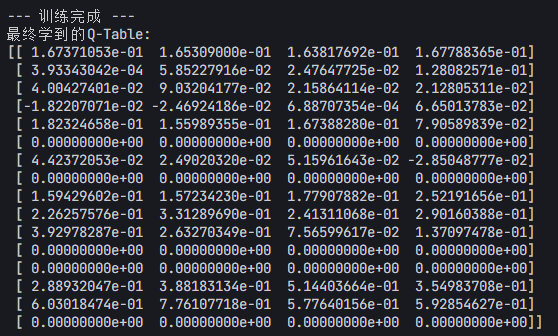
下面是一个 16 状态空间,4 动作的环境运行结果,在训练完成后,会得到一个Q table,每个位置对应智能体身处哪个位置,走哪一步的预期奖励。
参数解析
- 学习率 α : 学习率决定了智能体在每一次学习中,新信息对旧Q值的影响程度。简单来说,它控制了你“相信”新经验的程度。
- **折扣因子 γ **: 它决定了智能体是更看重眼前的即时奖励,还是更看重未来的长期奖励。
- 探索率 ϵ : 决定了智能体在“探索”未知动作和“利用”已知最优动作之间如何进行权衡。
- 通常在训练初期设置较高的 ϵ 值,鼓励探索;随着训练的进行,逐渐减小 ϵ 的值,让智能体更多地利用所学到的知识。这种策略被称为“ϵ-greedy”策略。
Qtable初始化
全部初始化为零 (Zeros Initialization)
- 这是最简单、最常用的方法。所有Q表格中的值都被初始化为0。
- 优点:简单易实现,且在大多数情况下效果很好。
- 原理:初始状态下,智能体对任何状态下的任何动作都没有任何偏好,所有动作都被认为是等价的,因此探索会非常随机。随着训练的进行,智能体通过与环境的互动,会慢慢学习到真实的Q值。
全部初始化为较小的随机值 (Small Random Values)
- 所有Q表格中的值都被初始化为较小的、接近0的随机数。
- 优点:可以打破对称性,确保智能体在一开始不会对所有动作都保持完全相同的偏好。在某些复杂问题中,这可能有助于加速学习过程。
代码实践,冰湖问题:
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
import random
# 1. 初始化环境
# is_slippery=True 开启了随机性,让问题更具挑战
env = gym.make('FrozenLake-v1', is_slippery=True)
# 2. 定义超参数 (Hyperparameters)
# 这些参数可以调整,以观察对学习效果的影响
total_episodes = 20000 # 总共玩多少局游戏
learning_rate = 0.1 # 学习率 alpha
gamma = 0.99 # 折扣因子 gamma
epsilon = 1.0 # 初始探索率
max_epsilon = 1.0 # 探索率最大值
min_epsilon = 0.01 # 探索率最小值
decay_rate = 0.0005 # 探索率的衰减率
# 3. 初始化Q-Table
state_space_size = env.observation_space.n
action_space_size = env.action_space.n
q_table = np.zeros((state_space_size, action_space_size))
# 用于记录训练过程中的成功率
rewards_per_episode = []
success_rate_per_episode = []
log_interval = 1000 # 每1000轮记录一次
# 4. 训练主循环
for episode in range(total_episodes):
# 重置环境,开始新的一局
state, info = env.reset()
terminated = False
while not terminated:
# 4.1 Epsilon-Greedy 策略选择动作
exploration_rate_threshold = random.uniform(0, 1)
if exploration_rate_threshold > epsilon:
# 利用 (Exploitation): 选择当前状态下Q值最大的动作
action = np.argmax(q_table[state, :])
else:
# 探索 (Exploration): 随机选择一个动作
action = env.action_space.sample()
# 4.2 执行动作并观察结果
new_state, reward, terminated, truncated, info = env.step(action)
# 如果游戏因为掉洞里或超时而结束,但没有到达终点,我们就给一个小的负奖励
# 原始环境只有在到达终点时奖励为1,其余都为0。这样的稀疏奖励很难学习。
# 这里我们做一点小小的奖励工程 (Reward Engineering)
if terminated and reward == 0:
reward = -0.1 # 掉洞里
elif not terminated:
reward = -0.01 # 每走一步都消耗一点成本
# 4.3 更新Q-Table (Q-Learning核心公式)
old_value = q_table[state, action]
next_max = np.max(q_table[new_state, :])
new_value = old_value + learning_rate * (reward + gamma * next_max - old_value)
q_table[state, action] = new_value
# 更新状态
state = new_state
# 4.4 探索率衰减
# 随着训练进行,我们越来越相信Q-Table,所以减少探索
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
# 记录该轮的最终奖励(成功为1,失败为-0.1)
rewards_per_episode.append(reward)
# 每隔一段时间计算并记录成功率
if (episode + 1) % log_interval == 0:
successful_episodes = sum(1 for r in rewards_per_episode[-log_interval:] if r > 0)
success_rate = successful_episodes / log_interval
success_rate_per_episode.append(success_rate)
print(f"Episode {episode+1}/{total_episodes} | "
f"Success Rate (last {log_interval} ep): {success_rate:.2f} | "
f"Epsilon: {epsilon:.4f}")
env.close()
# 5. 产出与评估
print("\n--- 训练完成 ---")
print("最终学到的Q-Table:")
print(q_table)
# 5.1 图表:展示成功率的变化趋势
plt.figure(figsize=(12, 6))
plt.plot(range(log_interval, total_episodes + 1, log_interval), success_rate_per_episode)
plt.title('Success Rate Over Episodes')
plt.xlabel(f'Episodes (x{log_interval})')
plt.ylabel('Success Rate')
plt.grid(True)
plt.show()
# 5.2 评估学习到的策略
print("\n--- 开始评估学习到的策略 ---")
total_eval_episodes = 100
successful_trips = 0
eval_env = gym.make('FrozenLake-v1', is_slippery=True)
for episode in range(total_eval_episodes):
state, info = eval_env.reset()
terminated = False
while not terminated:
# 在评估阶段,我们不再探索,完全使用贪心策略
action = np.argmax(q_table[state, :])
new_state, reward, terminated, truncated, info = eval_env.step(action)
state = new_state
if terminated and reward == 1.0:
successful_trips += 1
eval_env.close()
print(f"在 {total_eval_episodes} 次评估中,成功到达终点的次数: {successful_trips}")
print(f"最终策略成功率: {100 * successful_trips / total_eval_episodes}%")