正文
完整的KVcache包含 Prefill + decode。
# 带 KV Cache 的生成
kv_cache = {} # 每一层缓存 K, V
for step in range(max_new_tokens):
if step == 0:
# 第一步:处理所有 input tokens,填充 cache
logits, kv_cache = model(input_tokens, kv_cache=None)
else:
# 后续步:只送入上一步生成的 1 个 token
logits, kv_cache = model([last_token], kv_cache=kv_cache)
next_token = sample(logits[-1])
last_token = next_token
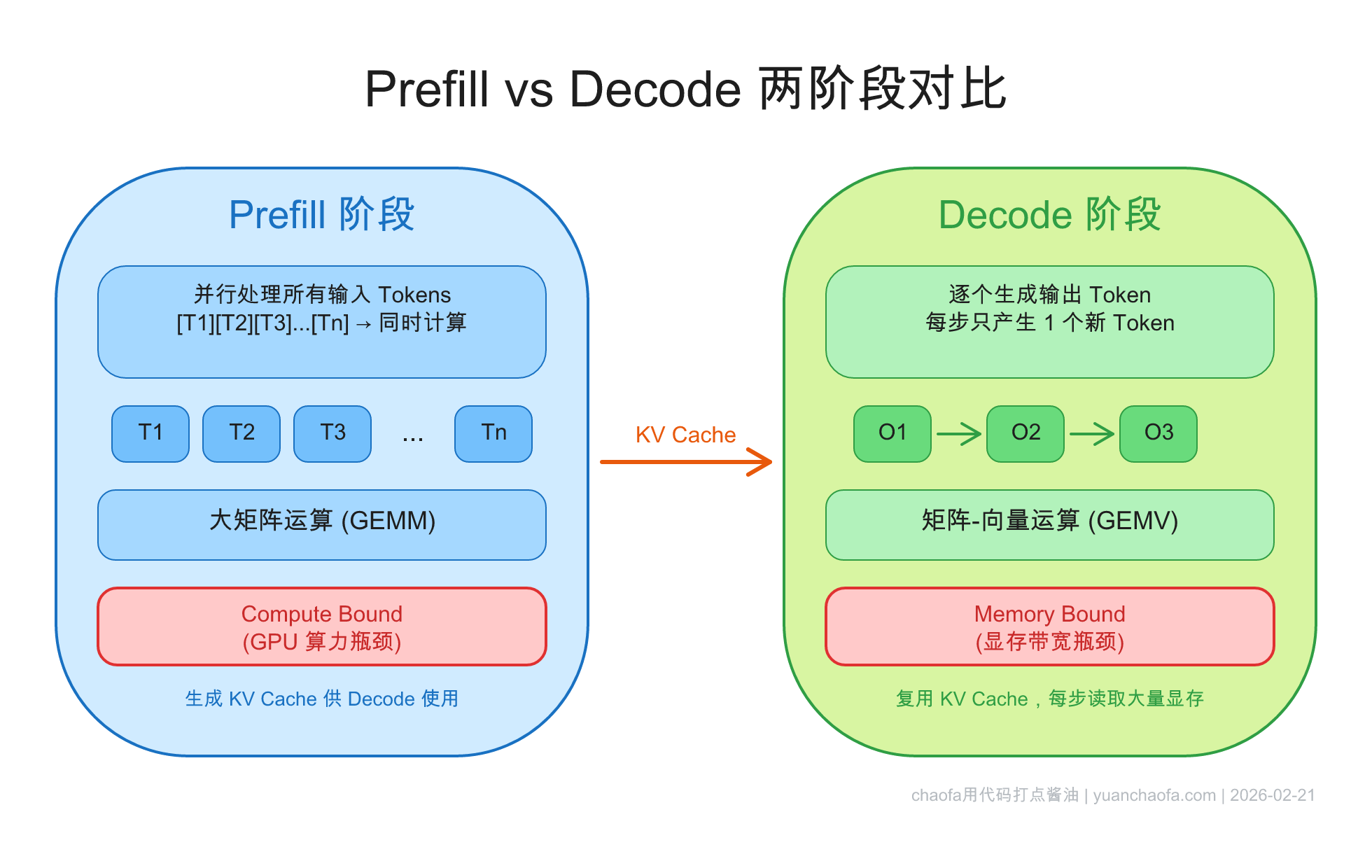
理解了 KV Cache 之后,我们可以把 LLM 推理过程清晰地分成两个阶段:Prefill 和 Decode。这两个阶段的计算特性截然不同,理解它们的区别对后面理解 Prompt Cache 非常关键。
causal attention的mask机制,仅在Prefill阶段生效,在decode阶段无效。
直觉:
用户输入都是一长串query:”白日依山”
Prefill阶段,因为query是 整体、一次性输入进模型中,需要设置 mask机制,让 “白”看不到”日依山”,”日”看不到”依山”…
但是decode阶段是逐个token生成,无需mask机制 挡住后面的内容(因为还没生成…)
Prefill 阶段(并行处理 input tokens)
Prefill 阶段就是上面伪代码中 step == 0 的那一步:模型一次性处理所有输入 token(system prompt + user message),为每一层、每个 token 计算出 K 和 V 并存入 cache。
用户输入 (Prompt):“白日依山”
- Prefill 阶段(并行): GPU 瞬间拿到了
["白", "日", "依", "山"]这 4 个 token。 它不需要先看“白”,再看“日”。GPU 会开足马力,同时计算:- “白”的特征(K, V)
- “日”在这个语境下的特征(K, V)
- “依”的特征(K, V)
- “山”的特征(K, V) 这 4 个 token 的计算是在同一瞬间、同一个矩阵乘法中并行完成的。算完后,把这 4 个字的 KV Cache 存进显存。
关键特点:
- 所有输入 token 可以并行处理
- 属于已知全部输入序列
- Prefill阶段 input tokens之间的 Attention mask 是 causal 的,但计算可以用矩阵乘法一次完成
- 计算量大:n 个 token × 所有层 × Q/K/V 矩阵运算
- Compute Bound:GPU 的算力是瓶颈,决定了首token时间 TTFT(Time To First Token)
:::info 问题:为什么Prefill阶段“已知输入”就可以不逐个执行?可以直接并行?
Prefill阶段的输入是整个input序列。假设你的输入 Prompt 有N 个 Token。在送入 Attention 层之前,它们会被转换成一个巨大的输入矩阵X(维度是 N * d,其中d 是隐藏层维度)。

随后,在进行attention分数计算时引入mask机制。
个人理解:
prefill阶段主要是针对input tokens进行预处理,预处理的流程就是计算得到每个token的QKV(用于后续decode生成)。因此,需要进行一个巨大的矩阵乘法计算。因为gpu的并行特性,可以快速进行矩阵计算,得到计算结果。
随后,通过掩码矩阵mask掉未来信息,使得每个token在计算attention时只使用过去token的qkv信息。
Mask 并不是直接作用在 QKV 上,而是作用在Q 和 K 相乘之后得到的“注意力分数”上。

问题:既然后续decode只用kv值,为什么还要有q和attention 分数?
个人理解:以”白日依山尽”为例,模型是逐个token进行处理的,当token “山”在计算前,都会得到Q_山、K山、V山,随后将K山、V山存储到之前的KVcache中,再使用Q山进行计算。
使用Q山 分别对 K白、K日、K依、K山进行点积计算,得到一个attention分数 List。[0,1,2,1]。
随后对attention分数List进行softmax得到[0, 0.25, 0.5, 0.25],随后与V矩阵相乘。
:::
Decode 阶段(逐 token 生成 )
Decode 阶段就是后续的 step > 0:每一步只输入 1 个 token,利用 KV Cache 做 Attention,生成下一个 token。
Decode 阶段(串行/自回归):
- 第 1 步: 模型看着前面存好的 Cache,经过计算,输出了第一个生成的字:
“尽”。 - 第 2 步: 现在要把
“尽”喂给模型。模型结合前面的 Cache 和新来的“尽”,输出下一个标点:“,”。 - 第 3 步: 把
“,”喂给模型,输出下一个字:“黄”。 在 Decode 阶段,你永远无法在算出“尽”之前提前算出“黄”,这就导致了它只能逐个处理。
关键特点:
- 每步只处理 1 个 token(无法并行,因为下一个 token 依赖上一个的输出)
- decode阶段无causal attention的mask机制。
- 每步的计算量其实不大——1 个 token 的 Q 乘以 cache 中所有 K/V
- 但每步都要从显存读取整个 KV Cache
- Memory Bound:GPU 的显存带宽是瓶颈,决定了生成每个后续 token 的平均时间 TPOT(Time Per Output Token