正文
如何理解float16、int4,是如何计算的?
参考下面的问题:
以Llama 7B模型为例,hidden_size为4096,也就说每个K,V有4096 个数据,假设是半精度浮点数据float16,一个Transformer Block中就有 4096* 2(每个元素占2字节) *2(K和V) = 16KB的单序列 K,V缓存空间,而Llama 2一共32个Transformer Block,所以单序列整个模型需要16 * 32 = 512KB的缓存空间。
每个Key和Value向量的大小:在Llama 7B模型中,每个Key(K)和Value(V)向量的大小是4096维,也就是说,每个K或V向量包含4096个元素。
数据类型:假设使用的是半精度浮点数(float16),每个元素占用2字节(16位 / 8 = 2字节)。
单个Transformer Block中的缓存空间需求:
每个K或V向量占用的空间为 4096×2=8192 字节。
每个Transformer Block中有两个这样的向量(K和V),所以总的空间为 8192×2=16384 字节(16KB)。
整个模型的缓存空间需求:
Llama 2模型包含32个Transformer Block。
整个模型的缓存空间需求为 16KB×32=512KB。
假如数据类型是int4,则每个K、V向量占0.5字节。
数据类型有哪些?
数据类型还有:
int8(1字节),int4(0.5字节),float16(半精度浮点型2字节)、float32(单精度浮点型,4字节)、float64(双精度浮点型,8字节)、bfloat16(2字节)
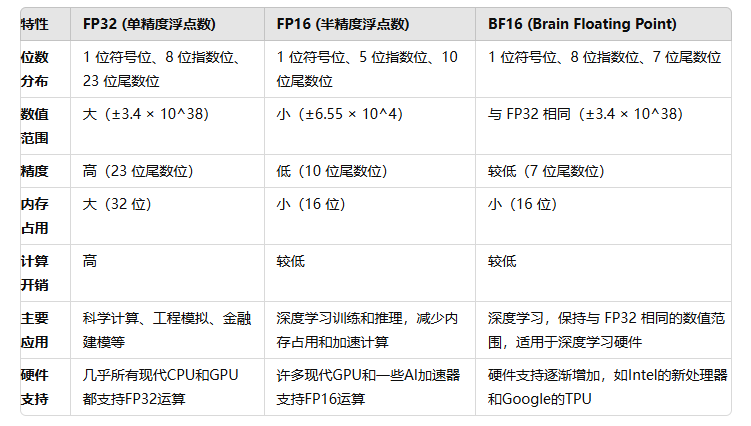
bfloat16(bf16)、float16(fp16)、float32(fp32)区别:
RoPE相对原来的绝对位置编码(Sinusoidal位置编码)有什么改进?
绝对位置编码,使用三角函数生成每个位置的唯一绝对位置信息(三角函数的主要用途是具有可去分析的周期性模式),然后与embedding的结果进行简单相加,从而使之后的向量计算中保留绝对位置信息。
这种绝对位置编码的方式在多层传递后会导致位置信息的稀释,也就是在处理较长的序列时能力有限,可能会导致梯度消失等问题。
RoPE不再是简单的加法,而是做内积,通过将m-n的相对位置嵌入到计算中,利用旋转变换将位置信息融入token表示中,强化了位置编码信息的作用。为了避免衰减特性(Q、K越远,注意力分数越低),θ保持了原来绝对位置编码的数值。
LLaMA模型为什么RoPE只旋转Q、K,而V是原数值?
在计算注意力权重时,旋转Q和K确保了位置编码对权重计算的影响。然而,V并不直接参与权重计算,它仅在加权求和中作为信息传递的一部分,用来生成最终的注意力输出。因此,将V保持原值可以避免不必要的干扰,确保信息的一致性和准确性。
head_dim 、hidden_dim 、n_local_heads 、seq_len、batch_size区别联系
hidden_dim 是整个模型中每个位置嵌入的维度。
head_dim是每个注意力头的维度,决定了每个头处理信息的能力。
n_local_heads是局部注意力机制中使用的头数,适用于局部注意力的变体
seq_len是输入或输出序列的长度,影响模型计算的范围和复杂度
batch_size是每次训练或推理过程中处理的样本数量
hidden_dim 是多头注意力中 head_dim 的总维度,head_dim 是 hidden_dim 的一部分。
hidden_dim = head_dim * num_heads(头总数)
6.为什么大模型都是decoder-only?
encoder架构在本文理解方面更出色,更适合进行embedding和分类任务。decoder则由于其自回归特性,更能捕捉语言的顺序和上下文信息,更适合文本生成。
decoder-only可以在不同的prompt下进行微调,适应各种对话任务。