正文
注意力机制通过查询(Query, Q)、键(Key, K)和**值(Value, V)三个向量来完成。
- Query (Q): 像一个“问题”,代表当前词想从其他词那里寻找什么信息。
- Key (K): 像一个“索引”,代表每个词能提供什么信息。
- Value (V): 像一个“答案”,代表每个词所包含的具体内容。
注意力机制的工作流程就是:用当前词的 Q 去匹配所有词的 K,找出最相关的词,然后根据相关性分数,对所有词的 V 进行加权求和,得到当前词的最终表示。
MHA & GQA & MQA & MLA 对比学习
MHA: Multi-Head Attention (多头注意力)
MHA 的做法是,将每个 token 的 Q、K、V 向量拆分成多个小份(即多个“头”),每个“头”独立地进行一次注意力计算。最后,把所有“头”的计算结果拼接起来,再经过一个线性层,得到最终的输出。
优势: 这种并行处理让模型能够同时捕捉到输入序列中各种不同类型、不同层面的信息,大大增强了模型的表达能力。
缺点: 在生成长文本时,每个 token 都会产生一套完整的 Q、K、V 向量,并且都需要被缓存(即 KV cache)。当序列长度增加时,KV cache 的大小会线性增长,导致占用大量的显存(GPU 内存),成为推理速度的瓶颈。
疑问解答
问题:输入数据是一致的,那么多个head是如何实现独立计算的?
回答:
- 输入到多头注意力层的数据是相同的。但每个“头”都有自己独一无二的权重矩阵。
- MHA会为每个头分配大小相同但随机初始化的权重矩阵,来实现独立的注意力计算。
- 在模型训练过程中,这些随机初始化的权重会通过反向传播和梯度下降算法进行调整。
**问题: **为什么多个头的结果要拼接起来,经过一个线性层?直接拼完输出不行吗?
回答:
- 拼接的含义不是相加,更像是追加。因此多个head的结果拼在一起,可能会导致结果特别长,和下一层的维度不匹配。
- 拼接后使用Liner,可以重塑size,更好的对接下一层。
- 拼接后使用Liner,可以学习如何将拼接后的长向量重新压缩成一个紧凑的、包含了所有关键信息的新向量,供后续的层继续处理。
- 这个Liner更像是一个信息筛选、信息整合层。是至关重要的一层。
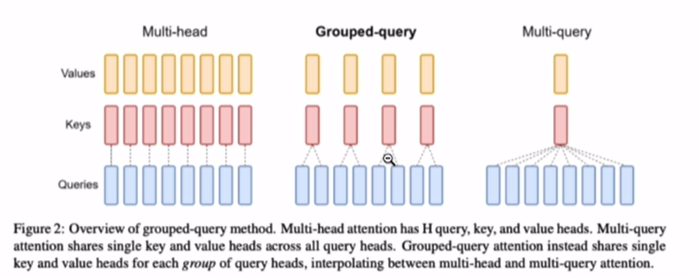
MQA: Multi-Query Attention (多查询注意力)
所有Q共享一组KV。
每个head对应一个query,所有head只有一对KV。
KV cache 大小大大减少,但整体效果较差。
GQA: Grouped-Query Attention (分组查询注意力)
- GQA 是一种介于 MHA 和 MQA 之间的折中方案
- 将 Q 向量分成 G 个组,然后为每个组生成一组 K 和 V 向量。当 G 等于 attention head 的数量时,GQA 就变成了 MHA;当 G 等于 1 时,GQA 就变成了 MQA。
- 许多现代大型语言模型(如 Llama 2、Mixtral)都采用了 GQA。
MLA: Multi-Head Latent Attention (多头潜在注意力) 【不太理解】
MLA 是 DeepSeek-V2 模型中引入的一种更新、更复杂的注意力机制。
MLA是MQA的低秩版本,通过将key和value压缩到latent空间存储,减少KV cache占用,并通过解压操作模拟多head注意力计算,性能不降低的同时减少了KVcache存储。
通俗解释: MLA 不再是简单地共享 K 和 V,而是通过一种“压缩和解压”的技术来优化。
- 在模型推理时,它不是直接存储完整的 K 和 V 向量,而是将它们压缩成一个更小、更紧凑的“潜在向量”(latent vector)并存储在 KV cache 中。
- 当需要计算注意力时,模型会从缓存中读取这个压缩的向量,并动态地“解压”成完整的 K 和 V 向量来使用。
优点:MLA 的主要优势在于极大地减小了 KV cache 的大小。因为它缓存的只是一个压缩后的向量,占用的显存比 MHA、MQA 和 GQA 都更少,这使得模型能够处理更长的上下文,特别是在需要处理超长序列时,优势非常明显。
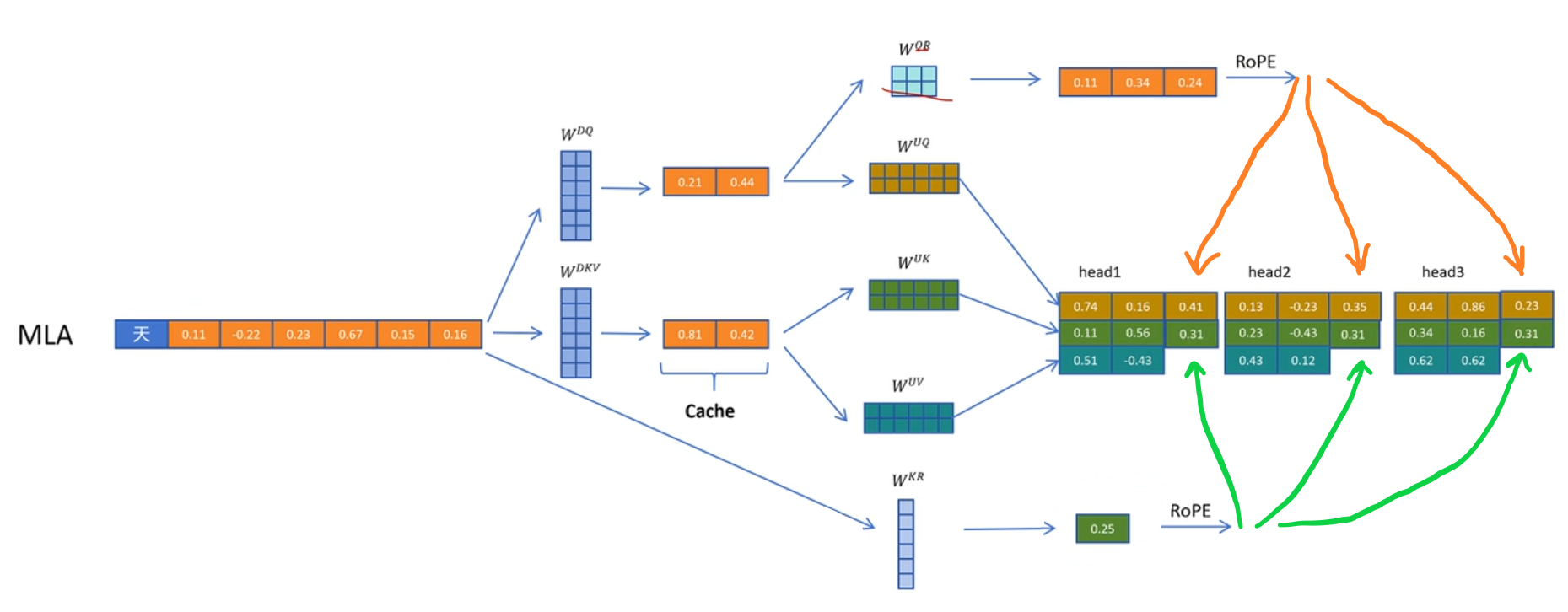
关于MLA中的ROPE
添加旋转位置编码:旋转位置编码一般是添加在Q和K上的,但是ROPE与输入的具体位置有关,无法像前面MLA attention中的其他参数矩阵一样可以合并并提前计算。因此这里采用了一个折中的解决方案,即额外维护了另一组压缩参数矩阵用于维护位置信息。
- query的压缩参数矩阵为WQR,key的压缩参数矩阵为WKR,其中R代表ROPE,指针对query和key分别进行压缩,用于旋转位置编码。 被压缩后的query和key分别应用于ROPE,并将应用过ROPE的query和key的对应向量拼接到原本解压后的query和value向量上,具体操作参见计算图。
- 被压缩后的query和key分别应用于ROPE,并将应用过ROPE的query和key的对应向量拼接到原本解压后的query和value向量上,具体操作参见计算图。
- 需要注意的是MLA中采取了MQA相同的设计,即不同head的query使用不同的位置编码后信息,不同head的key使用相同的位置编码后信息。这导致query和key的压缩矩阵维度不同,query的压缩维度是head数倍hidden size, key的压缩维度是1倍hidden size。
个人理解
- MLA 主要是为了减少KVcache, 节省计算和显存 。
- 所谓压缩,就是添加一个Liner进行线性投影。解压也是同理,模型需要学习这个 压缩矩阵 和 解压矩阵。
- 这里提到MLA的RoPE与原始RoPE不同,主要是由于标准的RoPE需要在计算 注意力分数 之前,针对每个token 的位置对QK进行旋转,从而引入位置信息。但MLA对QK进行了压缩,所谓的token位置已经不存在了,因此无法直接使用标准RoPE引入位置信息。
- MLA 的核心是把 Key 和 Value 向量压缩成一个“静态”的、与位置无关的潜在向量,并缓存起来。而 RoPE 是一种“动态”的位置编码,它的旋转操作依赖于每个 token 的具体位置索引。这两种机制在设计上是冲突的。
- 关于key和value使用同一个矩阵。虽然key通常用于计算注意力分数,value用于加权(权重矩阵)。但他们都来自相同的input,表示了相同token的内容信息。这里是假设 用于将 Key 向量中的内容信息压缩成低维表示的“知识”和用于压缩 Value 向量的“知识”是相似的,或者至少是可以通过同一个矩阵来学习的 。用来大幅提高效率。