正文
个人总结
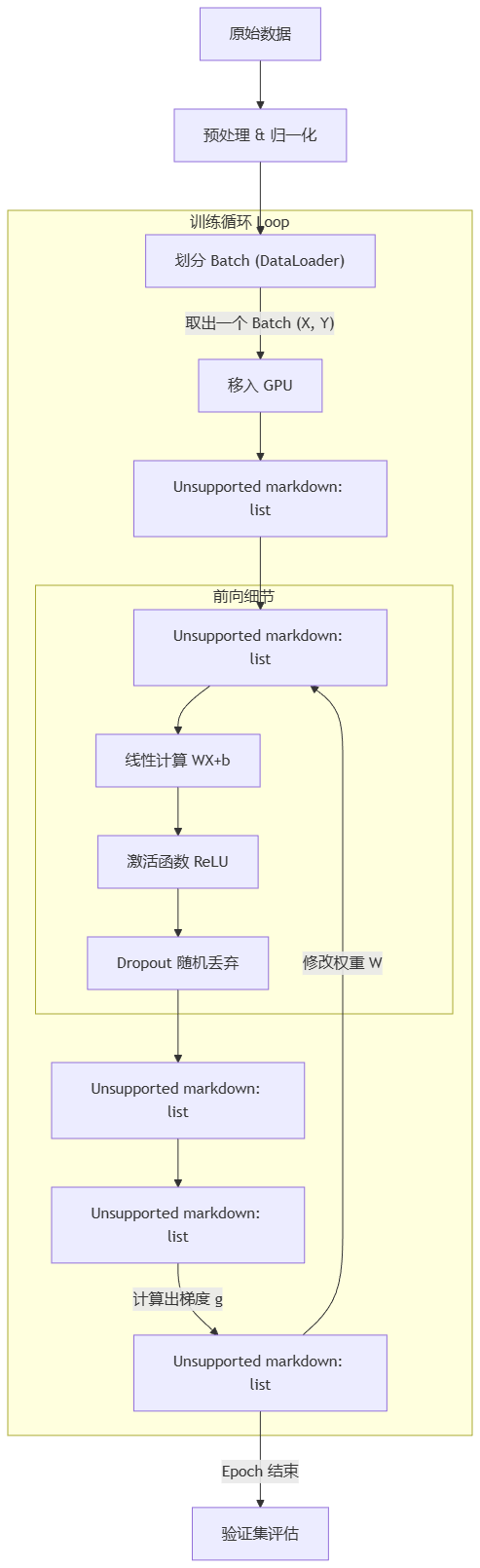
深度学习模型训练一轮,完整流程:前向传播、反向传播、参数更新
1. 数据准备阶段 (Data Preparation)
在训练开始前,必须将原始数据转化为模型可理解的张量(Tensor)格式,并建立高效的数据流水线。
1.1 数据预处理 (Preprocessing)
数据清洗:剔除无效数据,修正错误标签。
特征缩放/归一化 (Normalization):
目的:将输入特征统一到相似的数值范围(如 [0, 1] 或  ),防止梯度爆炸或消失,加速收敛。
),防止梯度爆炸或消失,加速收敛。
**公式示例**:
数据增强 (Data Augmentation):(针对图像/文本)
目的:通过随机旋转、裁剪、加噪等手段扩充数据集,作为一种隐式正则化,防止过拟合。
1.2 数据分批与加载 (Batching & Loading)
为了解决内存限制并利用矩阵并行计算,不能一次性将所有数据放入显存,也不能一条条训练,而是采用 Mini-batch 策略。
-
Dataset 封装:创建一个抽象类,定义如何读取单个样本 (X, Y)。
-
打乱 (Shuffling):
操作:在每一轮训练(Epoch)开始前,随机打乱数据顺序。
意义:消除数据间的相关性,防止模型通过记忆样本顺序来“作弊”,保证梯度的随机性。
-
分批 (Batching):
操作:将打乱后的数据按 Batch_Size(如 32, 64, 128)打包。
产出:生成一系列的批次,每个批次包含 N 个样本的矩阵。
2. 宏观架构:多轮训练 (Epochs & Iterations)
训练过程由两层循环构成:外层是“轮”,内层是“批”。
Epoch (轮):所有训练数据完整地过了一遍网络。
Iteration (步):处理完一个 Batch 的数据。
3. 微观核心:单批次数据的全流程 (The Lifecycle of a Batch)
这是深度学习最关键的部分。假设我们提取了一个 Batch 的数据,流程如下:
步骤 0: 数据迁移
- 操作:将
batch_x(特征) 和batch_y(标签) 从 CPU 内存复制到 GPU 显存。
步骤 1: 梯度清零 (Zero Gradients)
- 代码对应:
optimizer.zero_grad() - 详解:
- PyTorch 等框架默认会累加梯度(为了支持某些特殊模型)。
- 在开始计算当前 Batch 的梯度前,必须把上一个 Batch 遗留的梯度清零,否则更新方向会出错。
步骤 2: 前向传播 (Forward Propagation) —— “计算预测值”
【激活函数】【dropout】
数据流经网络各层,产生输出。
- 线性运算:
- 计算
 。
。 - 这是特征提取的基础矩阵乘法。
- 计算
- 激活函数 (Activation):
- 计算
 。
。 - 引入非线性因素,赋予神经网络拟合复杂函数的能力。
- 计算
- (Dropout:
- (仅在训练模式下触发) 根据概率 p,随机生成掩码矩阵 M(由0和1组成)。
- 计算

- 作用:强迫网络不依赖特定神经元,增强鲁棒性。
- 输出层:
- 经过多层堆叠后,得到最终预测值
 (Logits 或 Probabilities)。
(Logits 或 Probabilities)。
- 经过多层堆叠后,得到最终预测值
步骤 3: 计算损失 (Loss Calculation) —— “量化误差”
【损失函数】【正则化】
- 代码对应:
loss = loss_function(pred, target) - 详解:
- 计算预测值 与真实值
 之间的差异。
之间的差异。 - 正则化项加入:如果是 L1 、L2正则化,通常在此步骤加到 Loss 中。。
- 此步骤得到一个标量(Scalar)数值。
- 计算预测值
- loss函数:MSE、…
步骤 4: 反向传播 (Backward Propagation) —— “计算梯度”
- 代码对应:
loss.backward() - 详解:
- 这是链式法则 (Chain Rule) 的应用场。
- 从 Loss 开始,从后往前计算误差对每个参数 W 的偏导数(梯度)。

- 产出:计算出每个参数的梯度
 ,并将其存储在参数对象的
,并将其存储在参数对象的 .grad属性中。 - 注意:此步骤不修改权重 W 的值,只计算“该怎么改”。
步骤 5: 参数更新 (Optimization Step) —— “修正模型”
【优化器】【学习率】
- 代码对应:
optimizer.step() - 详解:
- 优化器读取步骤 4 算出的梯度。
- 结合学习率 (Learning Rate) 和历史动量 (Momentum),执行更新公式。
- 公式示例 (SGD):

- 公式示例 (Adam):结合一阶矩和二阶矩调整步长后更新。
- 【不确定这条的正确性】L2 正则化 (Weight Decay):通常在此步骤,在减梯度之前先对权重进行衰减操作。
4. 流程可视化图解