正文
正则化概念
- 正则化是一种用于 **防止模型过拟合** 的技术。
- 正则化通过在损失函数中引入额外的约束项,来 **限制模型的复杂性**,使模型更容易泛化。
- 不止局限L1、L2正则化,dropout、早停等也是正则化方法。
正则化的动机
在深度学习模型(如神经网络)中,随着 参数数量的增加,模型有更多的自由度去拟合训练数据。如果模型的容量太大,它可能会 记住训练数据中的每个细节(包括噪声和异常值),而无法在新的数据上泛化,导致 过拟合。
常见的正则化方法
问题:L1、L2正则化方法,为什么给loss加一个值,会影响梯度更新?为什么给loss加一个值,会让部分权重归0(L1)或接近0(L2)?
- L2 正则化(L2 Regularization,又叫权重衰减)L2 正则化 是最常用的一种正则化方法,它通过在损失函数中加上 权重的平方和,来惩罚大权重值,强迫模型学习 较小的权重,从而减少模型的复杂性。
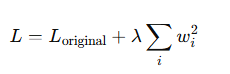
- L_original是原始的损失函数。
- λ 是正则化系数,控制正则化的强度(越大则正则化效果越强)。
- w_i 是模型中的权重。
作用:L2 正则化会 惩罚大的权重,使得权重趋向于较小的数值。L2使权重都趋于0,这样就不会有某个权重占比特别大。加深理解:L2正则化其实 对所有的权重 进行惩罚,鼓励模型的权重变得 更小,减小梯度更新的幅度。
- **对于大的权重: **如果权重很大,那么这个力就很大,模型会迅速将权重拉小。
- **对于小的权重: **如果权重已经接近 0,那么这个力就非常小,拉力几乎没有作用,权重不会再变得更小。
- L1、L2正则化的影响,不要只看loss,要看得到loss后更新梯度的公式。
- 原始梯度
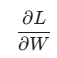 ,L2正则项梯度
,L2正则项梯度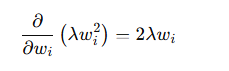 ,最后梯度相加。
,最后梯度相加。 - 这一步 求偏导 = 求梯度
应用场景: L2 正则化非常适用于 线性模型 或 深度神经网络,尤其是在没有太多需要被“选择”的特征时。
λ取值:非负实数(λ≥0)。
λ = 0 时,相当于 没有正则化。
λ → ∞ 时,正则化项的影响变得非常强,最终可能导致 权重接近零,模型变得 过于简单。
λ常规取值范围:[0.01, 1.0]
传统小模型,通过交叉验证、网格搜索确定λ最佳值。
- **L1 正则化(L1 Regularization) **
L1 正则化 通过在损失函数中加入 权重的绝对值之和,来惩罚权重值较大的情况。
与 L2 不同,L1 正则化的效果是 稀疏化 权重,导致 很多权重变为零。
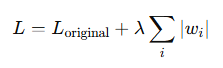
- L_original 是原始损失函数。
- λ是正则化系数。
- w_i 是模型中的权重。
作用:L1 正则化会 使部分权重变为零,从而使得模型更加稀疏,减少特征的使用,也能够在某些情况下起到特征选择的作用。
应用场景: 在 稀疏数据(如文本数据的 TF-IDF 向量)中,L1 正则化常用于 稀疏模型,如 Lasso 回归。
为什么文本数据通常是稀疏的?
主要来源于文本中的 单词特征。在文本中,虽然字典的大小可能很大,但 每个文档只包含字典中的一小部分单词,因此生成的 特征矩阵是稀疏的。
文档-词矩阵通常是** 高纬度、低密度** 特性。
λ取值:非负实数(λ≥0)。
λ = 0 时,相当于 没有正则化。
λ → ∞ 时,正则化项的影响变得非常强,最终可能导致 权重接近零,模型变得 过于简单。
λ常规取值范围:[0.01, 1.0]
传统小模型,通过交叉验证、网格搜索确定λ最佳值。
- Dropout方法
Dropout 是一种在训练过程中随机 丢弃神经网络中的一部分神经元 的正则化技术。
原理: 在每一轮训练中,Dropout 会随机选择一定比例的神经元,将它们的输出 设为零。这样可以防止网络对某些神经元过度依赖,迫使模型在训练时更加 鲁棒。
实现方式:通过生成一个掩码矩阵,与之按元素相乘(哈达玛积(Hadamard Product) )。
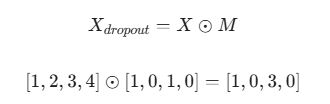
应用场景:用于 卷积神经网络(CNN) 和 全连接神经网络(FCN) 中,通常在每个训练阶段随机丢弃 30%~50% 的神经元。
- 早停(Early Stopping)
早停是一种简单的正则化技术,在训练过程中,监视 验证集的性能,如果验证集的性能不再提升(或者开始下降),则提前停止训练,从而避免 过拟合。
原理:在训练过程中,定期计算验证集的损失或准确率。如果验证集上的性能开始 恶化(即过拟合的迹象),则停止训练。
- 数据增强(Data Augmentation)
数据增强 是通过对训练数据进行 变换(如旋转、缩放、裁剪等),生成新的训练样本,以 增加训练数据的多样性,从而提高模型的泛化能力。
作用:通过增加训练数据的多样性,模型不容易记住训练数据的细节,从而提高模型在新数据上的表现。