正文
DP、TP、PP、CP技术概览
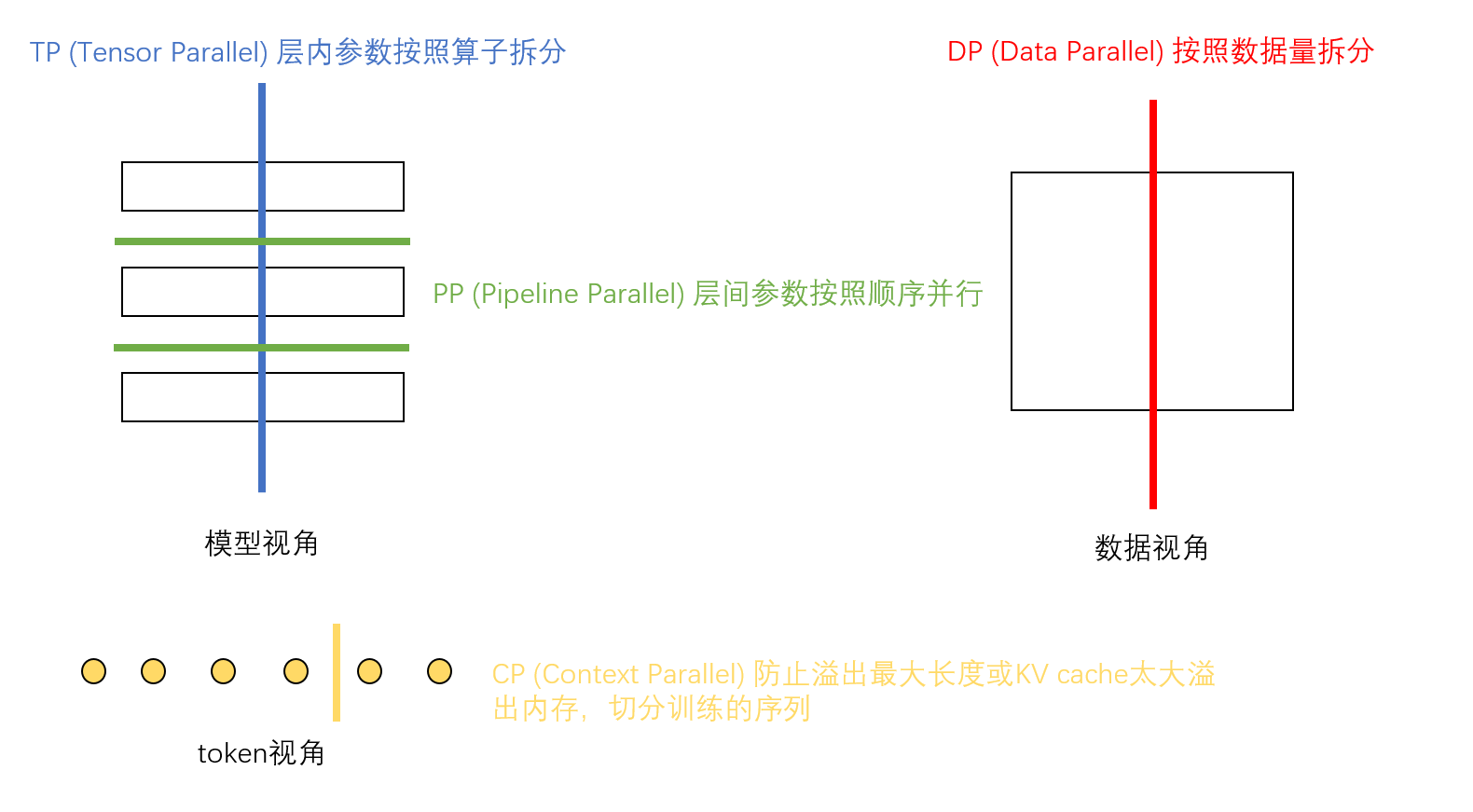
DP(数据并行)
每张卡单独存一个模型和部分数据,各部分训练完同步梯度。梯度reduce前需要需要裁剪。
- 优点: 简单易实现,对模型本身没有改动,应用最多。
- 缺点: 每张卡都要存一个完整的模型,如果模型太大,单卡内存无法容纳时就失效了。
# 假设模型有三层:L0, L1, L2
# 每层有两个神经元
# 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
a1 | b1 | c1
GPU1:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
a1 | b1 | c1
TP(张量并行/模型并行)
每张卡存模型的层内一部分,需要根据算子进行拆分(与ZeRO3区分来记),需要通信中间结果。
不是所有算子都适合并行,需要满足其并行计算的性质,例如矩阵乘法,多项加。
- 优点: 解决了单个模型太大,单卡无法容纳的问题。
- 缺点: 实施复杂,需要根据具体的运算(如矩阵乘法)进行拆分,而且通信量很大,会增加延迟。不是所有操作都适合拆分。
# 假设模型有三层:L0, L1, L2
# 每层有两个神经元
# 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
GPU1:
L0 | L1 | L2
---|----|---
a1 | b1 | c1
PP(流水线并行)
每张卡存模型的某几层,训练时每个batch依次进入对应层的卡进行计算。
- 优点: 解决了模型过大问题,相比TP,通信频率低,减少了通信开销。
- 缺点: 存在“气泡”效应,当第一个节点还没完成任务时,其他节点都处于等待状态,设备利用率不高。
- **气泡 **: 由于每张卡之间的计算存在依赖,导致设备因等待产生的空闲时间被称为气泡(bubble)
# 假设模型有8层
# 两张卡
====================== =====================
| L0 | L1 | L2 | L3 | | L4 | L5 | L6 | L7 |
====================== =====================
GPU0 GPU1
# 设想一下,当GPU0在进行(前向/后向)计算时,GPU1在干嘛?闲着
# 当GPU1在进行(前向/后向)计算时,GPU0在干嘛?闲着
# 为了防止”一卡工作,众卡围观“,实践中PP也会把batch数据分割成
# 多个micro-batch,流水线执行
为缓解气泡问题,提出了Gpipe和pipeDream(1F1B)方式进行PP。但都未完全解决气泡问题,只是缓解。
F和FWD,前向传播。B是BWD,反向传播。
传统PP:所有batch前向计算后,才开始反向传播。
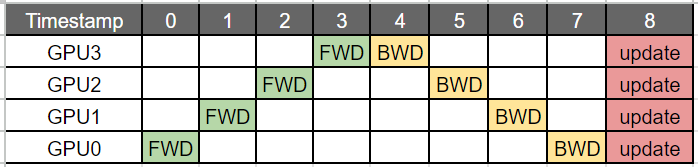
Gpipe:将原始的mini-batch分成更小的micro-batch,通过缩短等待时间减少气泡。所有microbatch前向计算结束后,才开始反向传播。
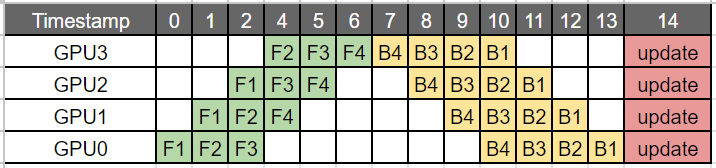
pipeDream:在GPipe的基础上,当一个micro-batch的所有前向计算完成后,立即进行反向传播。相比于GPipe事实上气泡没有显著减小,但是内存管理更好,中间结果利用完后,可以更早地释放,内存使用峰值更低。事实上正向计算和反向传播所消耗的时间不同,正向反向交替之间会存在一些气泡。
CP(上下文并行)
每长卡存输入序列的一部分,防止训练数据序列长度超过最大长度或KV cache太大显存溢出。
- 优点: 解决了训练时序列长度过长导致显存溢出的问题,或在推理时 KV Cache 过大导致的显存溢出。
- 缺点: 实施较为复杂,需要管理不同卡之间的上下文信息同步。
需要注意的是:
- DP,TP,PP 是3D并行,大部分大型模型的训练都基于这三种并行策略的组合。
- DP,TP,PP,CP是4D并行
优化器并行——ZeRO技术
背景:数据并行由于简单易实现,但缺点也很明显,每张卡都存储一个模型,此时显存就成了模型规模的天花板。如果有N张卡,系统中就存在N份模型参数,其中N-1份都是冗余的,我们有必要让每张卡都存一个完整的模型吗?系统中能否只有一个完整模型,每张卡都存 参数,卡数越多,每张卡的显存占用越少,这样越能训练更大规模的模型。
ZeRO(Zero Redundancy Optimizer)是一种Deepspeed提出的,用于大规模模型训练的优化技术,它通过智能地管理模型参数、梯度和优化器状态的存储和通信,来有效减少内存占用。主要用于替代 数据并行(DP)策略。
ZeRO各阶段对比表格
| 特性 | ZeRO-1 (Stage 1) | ZeRO-2 (Stage 2) | ZeRO-3 (Stage 3) | Offload 策略 | | — | — | — | — | — | | 主要分区对象 | 优化器状态 | 优化器状态 + 梯度 | 所有模型状态(优化器状态+梯度+模型参数) | 主要是优化器状态,从GPU卸载到CPU或硬盘。 | | 显存节省效果 | 中等:减少了优化器状态的冗余存储。 | 较好:在 ZeRO-1 的基础上,进一步减少了梯度的冗余存储。 | 最佳:消除了所有模型状态的冗余,理论上可达 N 倍节省。 | 额外节省:在 ZeRO-2 或 ZeRO-3 的基础上,进一步将状态从 GPU 卸载到 CPU。 | | 通信开销 | 类似传统数据并行 (DP),开销适中。 | 类似传统数据并行 (DP),开销适中。 | 较高,需要频繁的 AllGather 操作来动态收集参数。 | 增加 GPU-CPU 之间的数据传输开销,但通常是异步的。 | | 实现复杂性 | 最低,对模型代码侵入性小。 | 较低,在 ZeRO-1 基础上增加分区。 | 最高,需要动态管理参数的加载和卸载。 | 中等,需要管理 GPU 和 CPU 之间的数据流。 | | 解决的主要问题 | 减少 GPU 显存占用,让 Adam 等优化器能够应用于更大模型。 | 进一步减少 GPU 显存占用,支持更大的模型。 | 突破 GPU 显存的硬性限制,让训练万亿参数模型成为可能。 | 突破 GPU 显存的硬性限制,让单卡也能训练大模型。 | | 适用场景 | 训练百亿参数级别模型,对显存有一定要求。 | 训练千亿参数级别模型,需要更高效的显存利用。 | 训练万亿参数级别超大模型,显存是最大瓶颈。 | 在 ZeRO-2 或 ZeRO-3 基础上,需要进一步扩容内存,或在单卡上训练大模型。 |
Adam和混合精度 概念导读
- Adam优化器:在SGD基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)。
- 混合精度训练:字如其名,同时存在fp16和fp32两种格式的数值,其中模型参数、模型梯度都是fp16,此外还有fp32的模型参数,如果优化器是Adam,则还有fp32的momentum和variance。
模型在训练时出了总计包含四个部分的内容,包括参数,梯度,优化器状态和激活值。其中除了激活值都是可以并行的。
ZeRO将模型训练阶段,每张卡中显存内容分为两类:
- 模型状态(model states): 模型参数(fp16)、模型梯度(fp16)和Adam状态(fp32的模型参数备份,fp32的momentum和fp32的variance)。假设模型参数量B,则共需要2B+2B+(4B+4B+4B)=16B的字节存储,可以看到,Adam状态占比75% 。
- 剩余状态(residual states): 除了模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
GPT-2含有1.5B个参数,如果用fp16格式,只需要3GB显存,但是模型状态实际上需要耗费24GB!相比之下,激活值可以用activation checkpointing来大大减少,所以模型状态就成了头号显存杀手,它也是ZeRO的重点优化对象。而其中Adam状态又是第一个要被优化的。
为此,提出了ZeRO-1、ZeRO-2、ZeRO-3技术。
ZeRO-0(Stage 0)
原始数据并行。原始DP策略。
ZeRO-1(Stage 1)
ZeRO-1 是 ZeRO 技术的最基础阶段,它主要针对优化器状态(Optimizer States)进行分区。
- 优化器状态:这指的是 Adam、AdamW 等复杂优化器在训练时需要维护的额外信息。例如,Adam 优化器会为每个模型参数存储其一阶矩(first moment)和二阶矩(second moment)的估计值,这些状态通常是
fp32格式,内存占用量是fp16模型参数的 2 倍。 - 分区方式:在 ZeRO-1 中,每个 GPU 仍然存储完整的模型参数和梯度,但每个 GPU 只存储所有优化器状态的 1/N。
- 优点:在不改变数据并行(DP)通信开销的情况下,显存占用可以减少大约 2/3。对于训练大模型来说,这是一个巨大的进步。
ZeRO-2(Stage 2)
ZeRO-2 在 ZeRO-1 的基础上,进一步对梯度(Gradients)进行了分区。
- 梯度:在反向传播时计算出的、用于更新模型参数的数值。
- 分区方式:在 ZeRO-2 中,每个 GPU 不仅存储所有优化器状态的 1/N,还会存储所有梯度的 1/N。
- 优点: 这样做的好处是,在反向传播计算完梯度后,每个 GPU 会保留自己负责的那部分梯度,并丢弃其他部分的梯度。这进一步减少了显存占用,能够支持训练更大的模型。ZeRO-2 的通信量和计算量与 ZeRO-1 相似,因此它通常是训练中推荐的起点,因为它提供了更好的显存效率而没有显著的性能损失。
ZeRO-3(Stage 3)
ZeRO-3 是 ZeRO 的最强阶段,它对所有模型状态(参数、梯度、优化器状态)都进行了分区。
- 模型参数(Parameters):模型本身的权重。
- 分区方式:在 ZeRO-3 中,每个 GPU 只存储模型所有参数、梯度和优化器状态的 1/N。
- 动态收集:由于每个 GPU 都没有完整的模型,因此在进行前向传播和反向传播时,如果某个 GPU 需要一个完整的参数层进行计算,它会从其他 GPU 动态地收集(AllGather)所需的参数,计算完成后再丢弃。
这种动态收集和丢弃参数的过程会增加通信开销,但它也提供了最极致的显存节省。理论上,显存占用可以降低到传统数据并行的 1/N,这使得训练万亿参数级别的模型成为可能。
offload策略
- offload 策略是 ZeRO-2 和 ZeRO-3 的增强版。 offload 策略则是在ZeRO-2 和 ZeRO-3的基础上,将这些状态(梯度、优化器状态,甚至模型参数)从 GPU 显存卸载到 CPU 内存,甚至更慢但容量更大的 NVMe 硬盘上。
- 主要将 优化器状态 从GPU卸载到CPU中,从而 显著减少 GPU 的显存占用。
- 多卡场景时,offload可以和ZeRO-2 或 ZeRO-3复用。
** 分级存储系统:**
- GPU 显存是最快但最小的存储空间
- CPU 内存是次快次大的
- NVMe 硬盘则是最慢但最大的。
问题:
ZeRO3 和TP 张量并行有什么异同?都是对模型内的参数拆分。
答:ZeRO3中的参数分片的方式,与张量并行的拆分方式类似。但ZeRO3不是按算子拆分。ZERO3前向后向时传递的是参数,张量并行传递的是计算结果。
个人理解
- ZeRO是替代DP数据并行的一种方法,因为传统DP需要每张卡保存完整的模型,利用率太低。
- ZeRO与流水线并行PP、张量并行TP不冲突。(AI说的)
- ZeRO-1将优化器状态分区、ZeRO-2 将优化器状态+梯度分区、ZeRO-3将优化器状态+梯度+模型参数分区。
- offload是在ZeRO-2 和ZeRO-3基础上,将优化器状态存入CPU,进一步减少显存占用。
- ZeRO中,有混合精度计算,因为优化器状态需要FP32(保证稳定性和收敛性),其他都可以FP16。
- [这个不懂]ZeRO3 和 TP是否冲突?不冲突!是不同维度对模型参数的拆分。在同时使用ZeRO3和TP时,可以认为ZeRO3是 在 TP 切分后的。因为TP传递最终计算结果,ZeRO3传递的是参数。
- TP 是对张量的值做切分来加速计算,ZeRO 是对参数存储做切分来节省显存。
- LLamafactory中默认集成TP、PP,TP是自动开启的,PP是需要手动开启。(AI说的)
3D并行
DP,PP,TP三者一起使用。数据并行在最外层,然后是流水线并行,最内层是张量并行。
4D并行
指DP,CP,PP,TP三者一起使用。数据并行在最外层,然后是上下文并行,然后是流水线并行,最内层是张量并行。