正文
GraphRAG是用来复杂问题查询,多跳查询的技术。https://github.com/microsoft/graphrag
https://i-study-everyday.online/archives/2025/09/graphrag-querying-overview.html
GraphRAG通过原始文档构建一个知识图谱,并针对密切相关的节点构建不同的社区、生成社区摘要,当面对用户提问时,每个社区摘要都被用于生成初步答案,最后总结所有社区的初步答案,生成最终答案。

关键概念
社区
社区报告
社区报告是在 GraphRAG 的索引阶段(Indexing Stage)预先计算和生成的,而不是在用户提问时实时生成的。 在将原始数据(文档)转化为知识图谱后,用户进行任何查询之前。这是系统准备知识库的关键步骤。
社区报告生成方式:LLM 的 Map-Reduce 提炼
社区报告的生成过程是一个结构化、由 LLM 驱动的提炼过程,核心步骤如下:
- 社区识别(Community Detection):
- 首先,使用图算法(如 Leiden 算法或 Louvain 算法)对已构建的知识图谱进行分析。
- 算法根据实体(节点)之间关系的紧密程度,将图谱划分为不同的社区(即主题集群)。
- 上下文收集(Context Collection):
- 针对每一个识别出的社区,系统会收集所有与该社区相关的原始数据:
- 该社区内的所有实体(节点)和它们的描述。
- 该社区内的所有关系(边)和它们的描述。
- 与这些实体和关系关联的原始文本片段(Text Chunks)。
- 针对每一个识别出的社区,系统会收集所有与该社区相关的原始数据:
- LLM 提炼(LLM Summarization):
- 将收集到的所有零碎信息(可能非常庞大)打包成一个或多个结构化的提示(Prompt),发送给一个大型语言模型(LLM)。
- LLM 被要求扮演“分析师”的角色,根据提供的所有信息,生成一份连贯、全面的自然语言报告,总结该社区的核心主题、主要见解和跨文档关系。
- 结果: 这份生成的文本就是社区报告。
查询方法
基础查询
本地查询
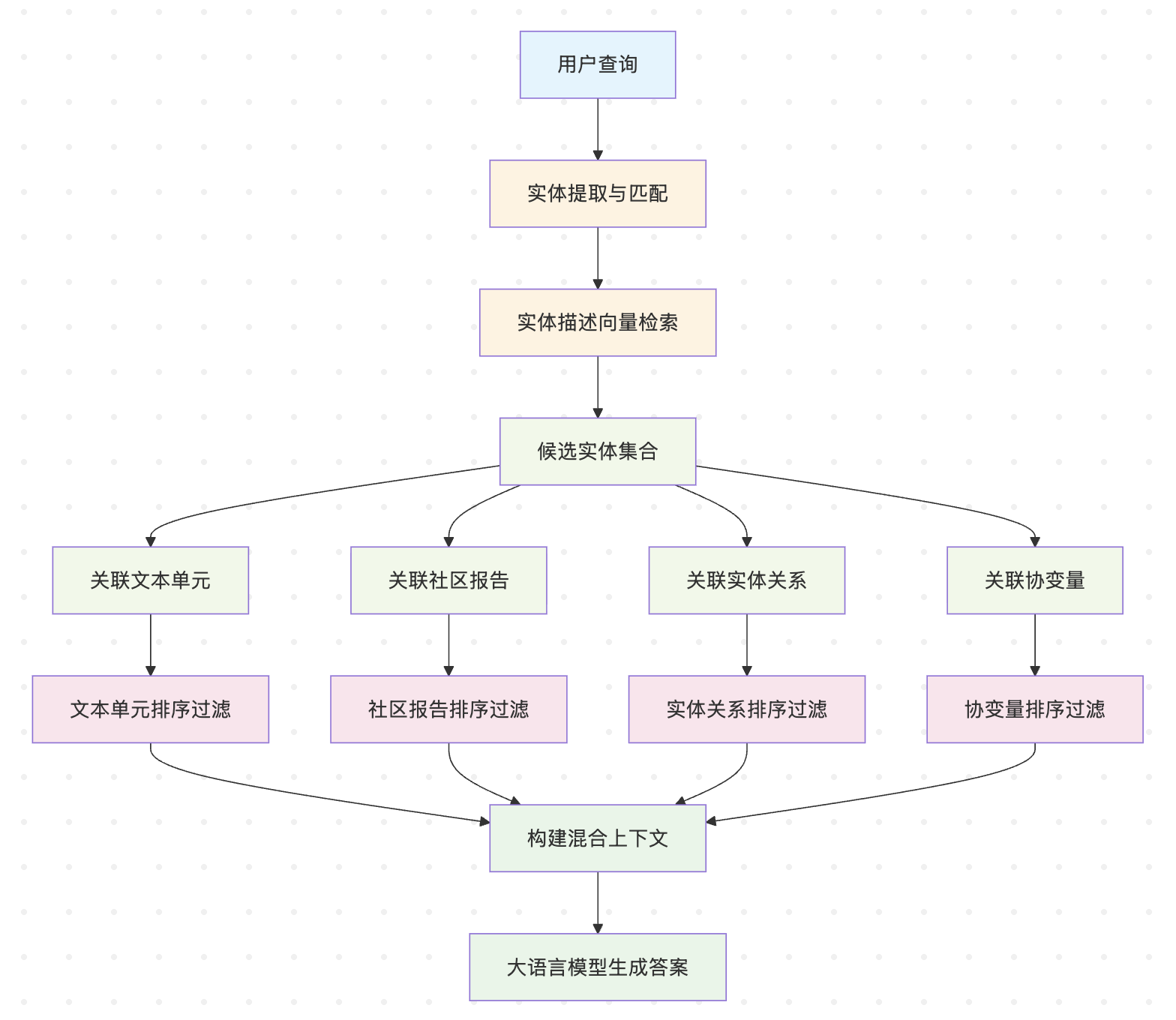 这个过程的详细步骤如下:
这个过程的详细步骤如下:
- 实体识别阶段:对用户查询进行向量化,在实体描述向量数据库中进行相似性搜索,获取语义相关的候选实体集合(Top-K);
- 上下文扩展阶段:
- 文本单元扩展:根据实体和文本单元映射关系,找到包含这些实体的原始文本片段(chunk);
- 社区报告扩展:根据实体和社区映射关系,获取相关的社区摘要报告(获取实体所在社区的摘要,这个摘要是在构建图谱时生成的。生成过程是调用LLM对该社区内全部实体、关系进行抽象总结。);
- 实体关系扩展:使用实体名称和描述等信息构建实体上下文,然后再依次查找与实体相连的关系构建关系上下文(找到与选定实体相连的实体,获取“实体-关系-实体”。);
- 协变量扩展:如果配置了协变量提取,还会包含相关的声明信息(对某实体、关系的额外描述信息);
- 排序过滤阶段:
- 排序:对每类候选数据进行重要性排序,比如对于文本单元来说,关系数量更多优先级更高,对于社区来说,包含的选中实体数量更多的优先级更高(调用LLM进行打分,0-100,过滤0分的);
- 过滤:根据 token 预算进行过滤,确保上下文适合大语言模型的输入窗口(在保证不超过token 预算时,按顺序填入);
- 答案生成阶段:将过滤后的多源信息整合成结构化上下文,调用大模型生成最终答案;
本地搜索的过程就像是一次从图谱中的特定节点出发,向外探索和收集信息的侦察任务,它的关键优势在于 多源信息融合 能力:通过文本单元保留原始文档的详细信息,通过知识图谱揭示实体间的复杂关系,通过社区报告提供结构化的主题总结。它特别适合需要理解特定实体及其关系的问题,