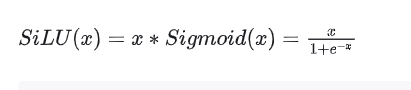正文
推理流程
prompt:输入的一段文本
tokenization:将文本进行tokenization,切分为单词或字符,形成token序列。
序列化->
[‘BOS’,’君’,’不’,’见’,’黄’,’河’,’之’,’水’,’天’,’上’,’来’,’,’ ,’奔’,’流’,’到’…‘与’,’尔’,’同’,’销’,’万’,’古’,’愁’,’EOS’]
假设语料库索引化->
[‘BOS’,’10’,’3’,’67’,’89’,’21’,’45’,’55’,’61’,’4’,’324’,’565’ ,’789’,’6567’,’786’…‘7869’,’9’,’3452’,’563’,’56’,’66’,’77’,’EOS’]
embedding:文本经过tokenization后变为了token序列,embedding将每个token映射为实数向量,名为embedding vector
‘BOS’-> [p_{00},p_{01},p_{02},…,p_{0d-1}]
‘10’ -> [p_{10},p_{11},p_{12},…,p_{1d-1}]
‘3’ -> [p_{20},p_{21},p_{22},…,p_{2d-1}]
…
‘EOS’-> [p_{n0},p_{n1},p_{n2},…,p_{nd-1}]
位置编码:对于Token序列中的每个位置,添加位置编码(Positional Encoding)向量,以提供关于Token在序列中位置的信息。位置编码是为了区分不同位置的Token,并为模型提供上下文关系的信息。
自回归生成:在生成任务中,使用自回归(Autoregressive)方式,即逐个生成输出序列中的每个Token。在解码过程中,每次生成一个Token时,使用前面已生成的内容作为上下文,来帮助预测下一个Token。很多模型都是自回归模型
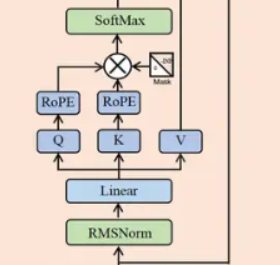
LLama模型结构
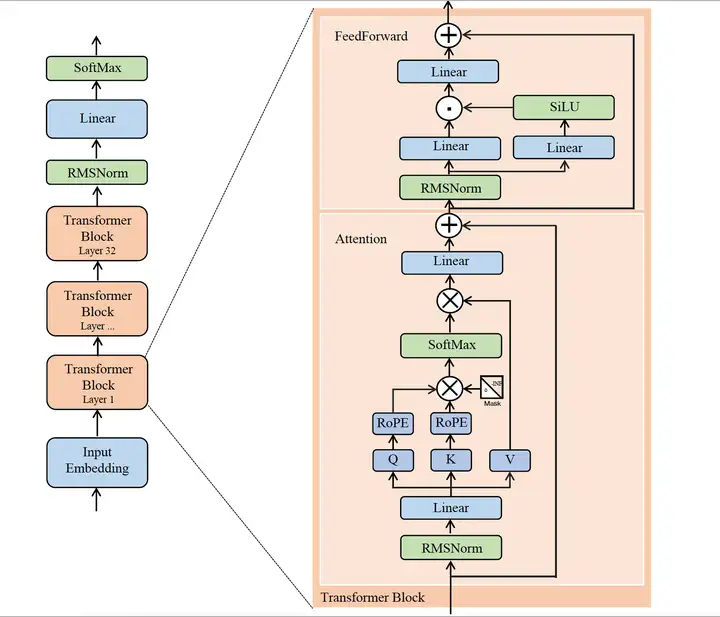
LLama用了32个transformer块,与标准transformer的区别如下:
前置的RMSNorm
Q在与K相乘之前,先使用RoPEKV Cache,Group Query Attention(GQA)
FeedForward层
RMSNorm
LLama模型首先经过embedding层,然后依次经过32个transformer。
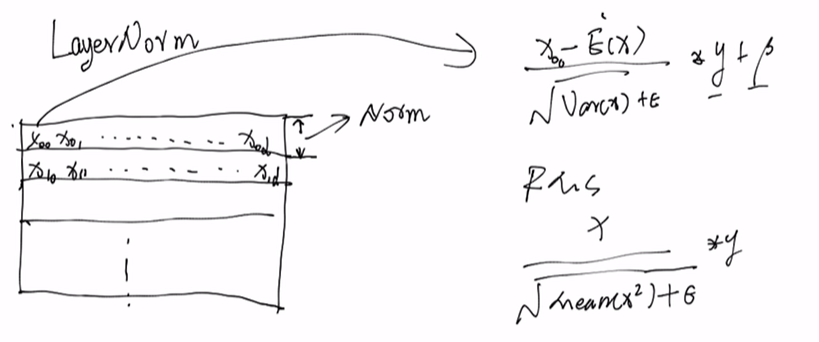
其中,LLama的transformer没有使用LayerNorm(标准的transformer)进行tensor的归一化,而是RMSNorm。
RMSNorm是LayerNorm的变体,RMSNorm省去了求均值的过程,也没有了偏置β,
RMSNorm在分子上移除了均值项,这点在论文里面有实验解释re-center的操作没有很重要
RMSNorm仅使用平方根的均值,与使用方差相比,可以降低噪声的影响
(个人认为最重要的)简化了LayerNorm, 相比较以前均值和方差的计算量,现在只需要计算RMS, 大大减少了计算时间(7%-64%)作为开源模型,使用者没有那么强的算力,因此减少cost能为开源项目带来更多的优势
| LayerNorm公式 | RMSNorm的公式 |
|---|---|
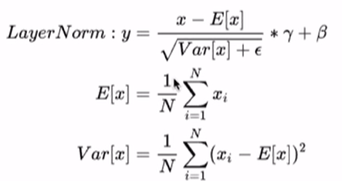 |
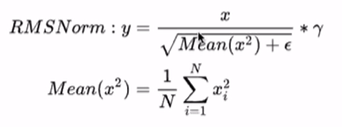 |
notes:
在进行Norm时,以某行向量为单位,E(x)是这一行的均值,Var(x)是这一行的方差(RMSNorm中没有这两项了)。
Norm层输入shape:[batch_size, seq_len, hidden_dim],输出不变,不会改变,只是做一个归一化。
Attention
下图为了便于理解,只是单头注意力,实际是多头,是多个单头并行。
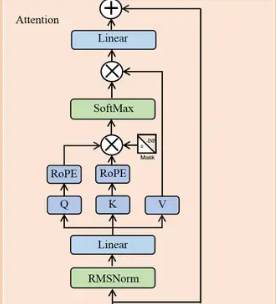
注意力机制输入shape:[batch_size, seq_len, hidden_dim],和Norm归一化的输出一致。
Linear层的weight: [hidden_dim, hidden_dim]
也就是 tensor 与 Linear的weight做乘法(这里是单batch_size,实际要考虑多batch_size)。
Linear层输出:
单batch_size时,linear的处理为:
[seq_len, hidden_dim] × [ hidden_dim, hidden_dim ] = [seq_len, hidden_dim]
多batch_size时,结果为:
[batch_size, seq_len, hidden_dim]
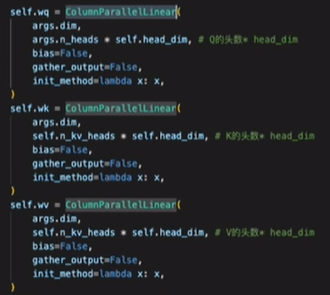
怎么得到QKV呢?
将输出与3个Linear层wq、wk、wv作乘法,分别得到Q、K、V
并不会改变原始的[batch_size, seq_len, hidden_dim],只是做权重乘法。
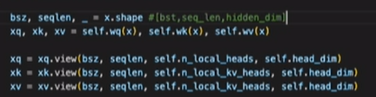
这里做了一个view,也就是reshape。得到的输出为
[batch_size, seq_len, n_local_heads, head_dim]
#n_local_heads 为多头注意力的头数,实际为多个单头并行。
attention计算
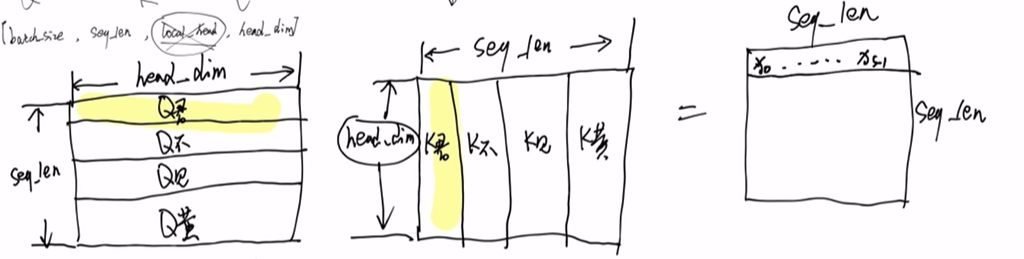
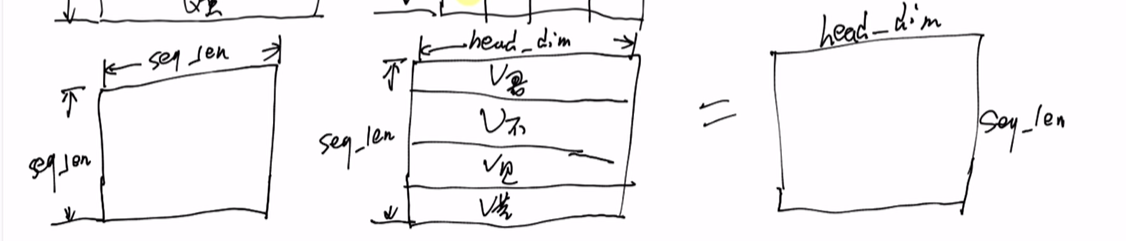
QKV的格式是一样的,都是[batch_size, seq_len, head_dim]
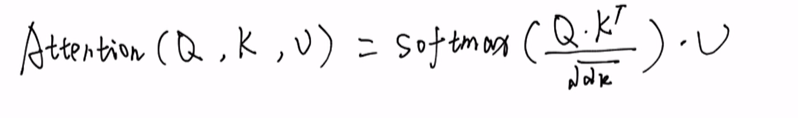
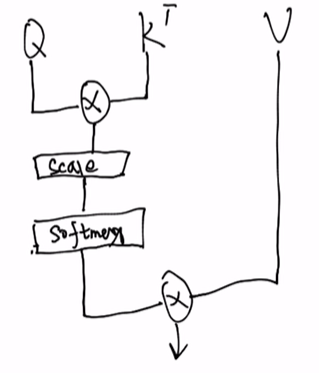
Q · K转置(后面还要再乘一个Mask矩阵,在下面)
再 乘 V
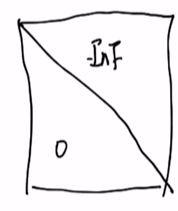
Mask
在Q·K转置后,加一个矩阵。
在NLP中,预测时,前面的字不能知道后面的字,
“君不见黄河之水”,“君”不能知道他后面的字,只能知道前面的字,因此需要 掩住,也就是降低其注意力(关注程度),因此可以下面的掩码矩阵进行相加。
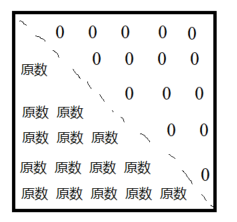
右上角是负无穷(-inf),左下角是0。
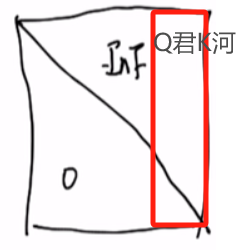
距离较远的2个字的向量,例如Q(君) × K转置(河)的结果,会与下图红色框的数字继续相加。得到的结果会是一个负无穷(-inf)。
距离较近的2个字的向量,会与左下角的0相加,不会有任何变化。
随后再进行softmax,公式如下:
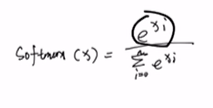
e的负无穷次幂,结果是0,这就可以将得到的Q·K转置结果的右上角置为0。
其他不为负无穷(-inf)的地方,softmax结果还是之前的数值(因为加的是左下角的0,任何数+0还等于原数)。
最终经过Mask的结果可能是下图,随后与V相乘:
KV cache
假设“将进酒:人生得” 来预测下一个”意”字,所以需要把“将进酒:人生得”进行token化后再进行Attention计算,如下图。
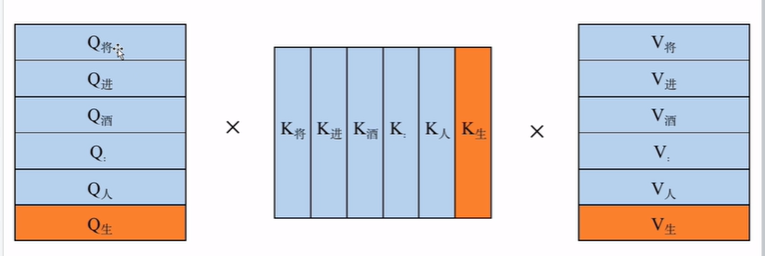
但是,其实已经把“将进酒:人生”所对应的Q,K,V进行过相关的运算,所以没必要在对他们进行Attention计算。
KV Cache便是来解决这个问题的:通过将每次计算的K和V缓存下来,之后新的序列进来时只需要从KV Cache中读取之前的KV值即可,就不需要再去重复计算之前的KV了。
对于Q,也不需要将所有Q都计算,只计算最新的Q_newtoken即可。如下图。只计算Q_newtoken与 K_newtoken 的乘积(Q_oldtoken计算完就不要了,K_oldtokens和V_oldtokens缓存起来)。
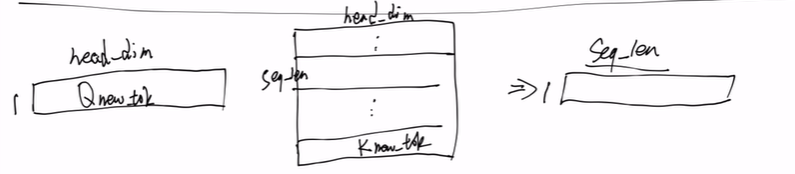
然后将结果与 V_newtoken 进行乘积。

解释1:至于为什么不用缓存Q? 我理解这是一种单向注意力机制,他只管每次进来的token与past tokens的注意力,而past tokens不会管后面token的注意力,所以就不需要Q_past_tokens,也就不需要缓存Q
解释2:Q表示当前步查询的词向量,K、V表示之前生成的词的表示。K类似储存了哪些信息,Q在K中进行相似度匹配,随后与V加权生成关注程度。从这个角度理解的话,Q是需要每一步都要动态计算的,无法缓存。因此可以进行kvcache,每一步只计算Q_newtoken。
解释3:这是因为Q通常只涉及当前时间步的数据,因此无需缓存。而K和V代表了上下文信息,它们在未来的每一个时间步都可能被用来与新的Q进行匹配。缓存K和V允许模型在处理长序列时避免重复计算,提升推理效率。
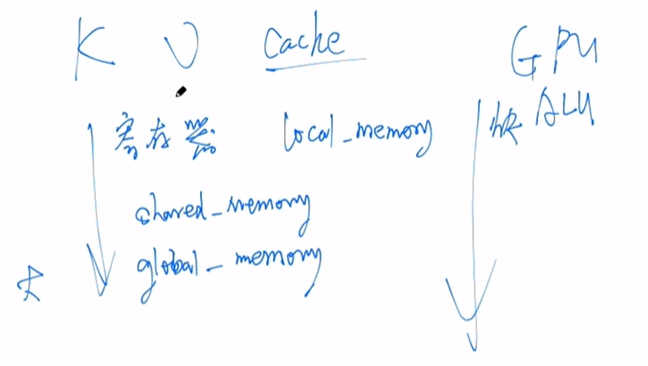
为什么可以进行cache,从GPU结构角度理解。
越靠近GPU的ALU(逻辑运算单元),速度越快
越远离ALU,内存越大
一般(SRAM)只有几十M的大小,7B的模型处理4096序列长度就需要512M的缓存空间了,更何况130B,所以cache一般存储在global memory(显存)中。
但是显存有一个明显的缺点,运算慢,这会导致一个问题Memory wall(内存墙)。简单来说就是处理器ALU太快,单内存读写速度慢跟不上,导致ALU算完在那等着你把数据读进来,影响性能。
解决Memory Wall(内存墙)的方法:
硬件层面,使用高速带宽内容(HBM)来提高读取速度,或者抛弃冯诺依曼架构,改变计算单元从内存读数据的方式,不再以计算单元为中心,而是以存储为中心,做成计算和存储一体化的”存内计算”,比如 忆阻器。
软件层面,引入优化算法,例如GQA。
GQA
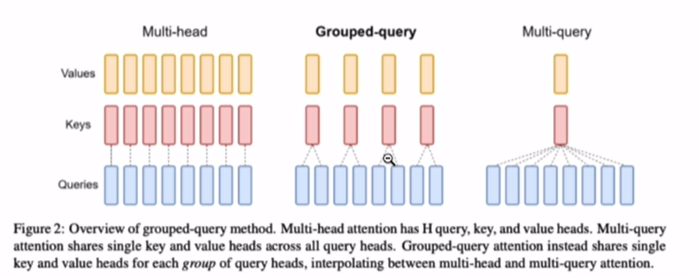
GQA是一种介于Multi-head和Multi-query(MQA)之间的形式。每2个(一组)head共享一个K、V。
MQA保留多头,但所有head的Q共享1个K、V,精度低。
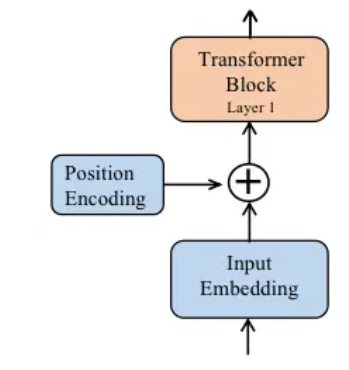
绝对位置编码为什么要位置编码:模型处理输入数据是不知道词的先后顺序,需要通过位置信息补充这一信息,如果没有位置编码“我和你”、“你和我”、“你我和”都是一样的。
在标准的Transformer中通常是在整个网络进入Transformer Block之前做一个位置编码,如下图所示
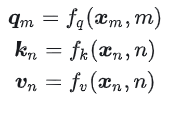

RoPE
通过绝对位置编码方式实现相对位置编码。
假设给q、k添加绝对位置信息,如下。
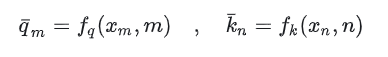
上述的q-、k-带有了m、n的绝对位置信息。之后在进行attention的计算时,需要计算q-、k-的内积。
但为了获取相对位置信息,需要使得内积的结果受m-n的影响即可。也就是说要满足如下:
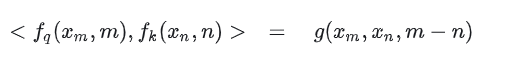

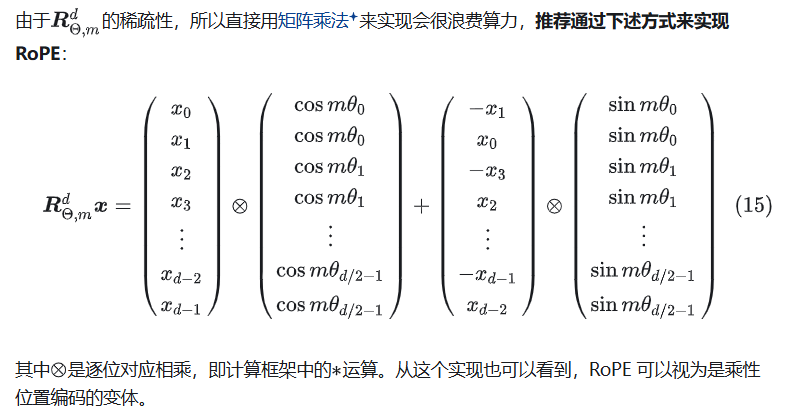
总结来说,RoPE 的 self-attention 操作的流程是:对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量,然后对每个 token 位置都计算对应的旋转位置编码。
接着对每个 token 位置的 query 和 key 向量的元素按照 两两一组 应用旋转变换(见上面一个公式),最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果(用qk变换后的结果计算内积)。
下面是论文原图。
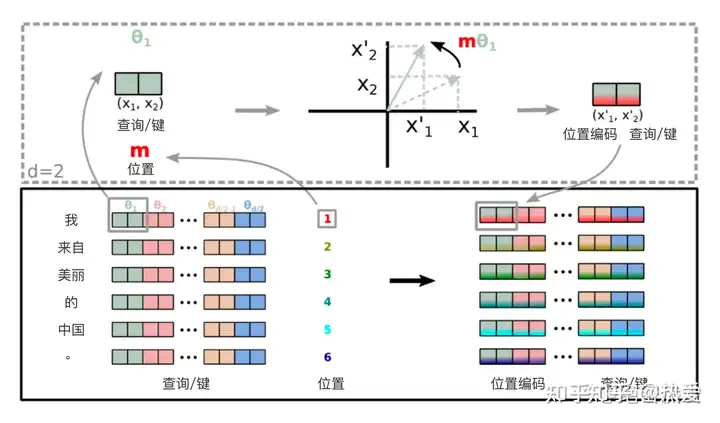
关于RoPE中的θ
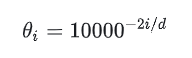
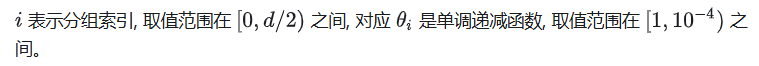
为什么这么设置?因为 远程衰减特性。向量k在q附近,注意力分数偏高、反之偏低
Feedforward Neural Network(前馈神经网络,FNN)
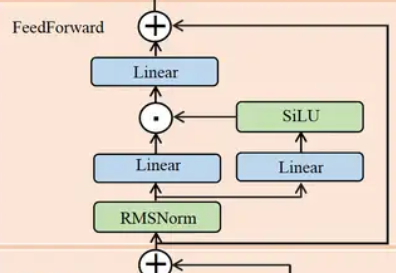
SiLU
与标准的Transformer一样,经过Attention层之后就进行FeedForward层的处理,但LLama2的FeedForward与标准的Transformer FeedForward有一些细微的差异,需要注意的地方就是SiLU